6_Hash_Table
6 Hash Table
使用范围
- Internal Meta-data
- Core Data Storage
- Temporary Data Structures (join 联表查询)
- Table Indexes
6.1 Design Decisions
- Data Organization
- Concurrency

unrealistic assumptions

Hash Function
- 计算速度和碰撞率的取舍
Hashing Scheme
- 静态哈希表
- 可扩展哈希表
6.2 hash functions

6.3 static Hashing Schemes
Linear probe hashing (线性探测哈希)
如果碰撞,存放到下一个空闲的槽;可能出现原来存在冲突的值被删除
Tombstone (墓碑):标记该位置有值被删除
Movement:将空槽之后的数据进行整理
重复的键问题
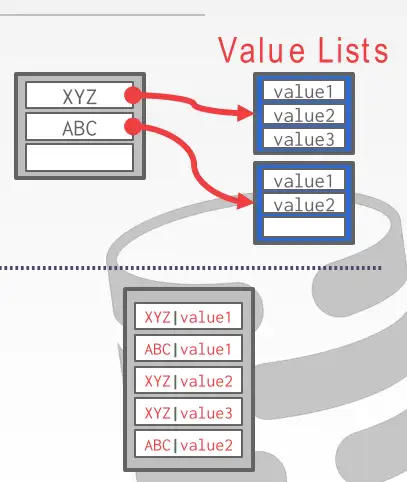
Separate Linked List:把每个键对应的键值存在特殊结构中,hash 表中存放指向该结构的指针
Redundant Keys:将键值一起作为键,存放在哈希表中
optimization
按照类型和大小对哈希表进行特例化实现
使用 hash table 存储元数据
使用 table+slot+version 来快速对 hash table 中的所有条目进行 Invalid
如果 table 的 version 与 slot 的 version 不匹配,将该 slot 作为空 slot 处理
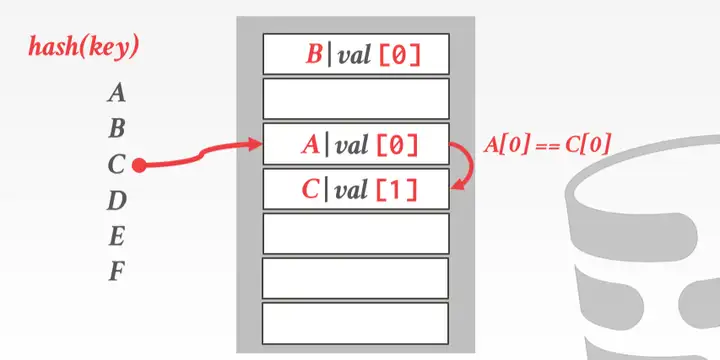
Robin Hood hashing
基于开放地址哈希的改进版,基本思路是”劫富济贫”, 记录每个元素的偏移量. 每次比较是比较每个 key 距离自己原本位置的距离(越近越富裕), 如果遇到一个已经被占用的 slot 且它比自己富裕, 就代替它的位置, 然后把它顺延到新的位置
Cuckoo hashing(布谷鸟哈希)
linear hash 是顺序 IO 而 cukoo hash 是随机 IO
建立多个散列表, 使用不同的哈希函数. 在插入时,检查每个表并选择任何有空闲插槽的表。如果没有表有空闲插槽,则从其中一个中删除该元素,然后重新散列它以找到新位置。
防止无限循环: 循环起来时用新的散列函数重建整个散列表

静态哈希结构缺陷
要求使用者能够预判所存数据的总量,否则每次数量超过范围时都需要重建 Hash Table。
动态哈希结构就可以 resize themselves on demand.
Dynamic Hash Table
支持动态按需扩容缩容
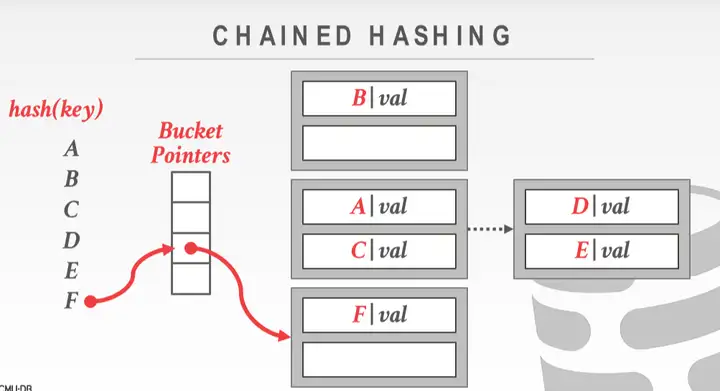
Chained Hashing
每个 key 对应一个链表, 每个节点是一个 bucket(可以存储多个元素).bucket 满了就在后面再挂一个 bucket
要处理并发性: 在桶上设置一个 latch
Java 中的实现则是做了简化, 每个 bucket 相当于只存放一个元素. 问题在于元素很多事链表会很长, 所以进行的优化(压缩成红黑树)
可以在 bucket pointers 中加入 bloom filter 来加快查找时的速度
如果不存在,Bloom filter 会返回 false,不必继续进行顺序查找

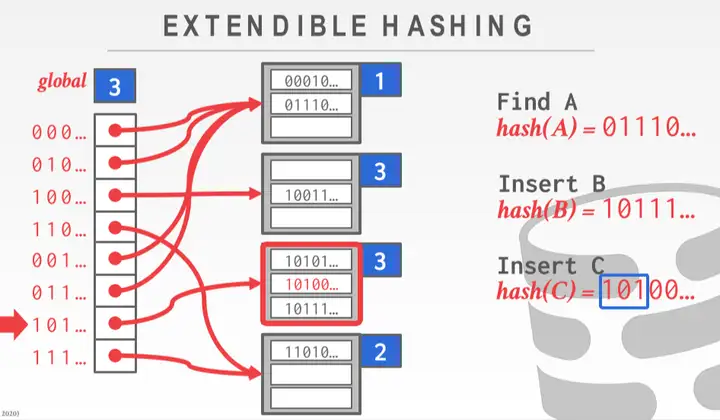
Extendible Hashing
基本思路是一边扩容,一边 rehash.
哈希函数得到二进制, 根据全局标志位决定看 hash 值的二进制前几位, 根据这个位数去决定扔到哪个桶里;
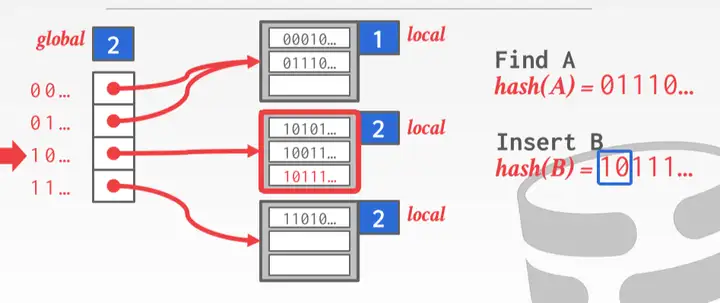
PS: 这里的桶代表第一位是 0, 前两位是 10, 11…
一旦桶满了就让全局标志位++, 然后各个桶再 rehash(桶的数量要变多)
Linear Hashing
维护一个 split 指针,指向下一个将被拆分的 bucket,初始 split 指针指向 0 号桶
每当任意一个 bucket 溢出(标准自定,如利用率到达阈值等)时,将指针指向的 bucket 拆分。
拆分后使用新的 hash function 对 split 指向的元素进行 rehash;每次溢出增加一个 bucket pointer
进行查找时,如果查找的元素在 split pointer 下面,使用原始的 hash function,否则使用新的 hash function

现在 17 应该被插入第二个桶, 但是已经满了,又不想挂新的桶. 那么对指针指向的桶(0 号)进行分裂, 对分割点指向的桶所包含的 key 采用新的 hash 函数进行分割(原来是 a % n, 改成 a % 2n). 17 也放在新的桶里
之前所有的”填满”不一定是完全满, 可以是比如到了 75%之类的…
当新增加的桶中没有元素,我们可以选择压缩/合并桶,减小存储的空间
