TimesharingOS
TimesharingOS
MultiprogOS
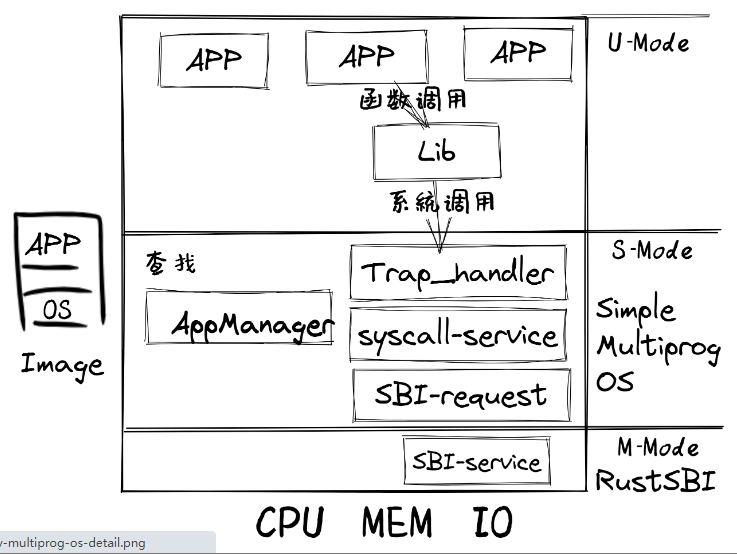
- Qemu把包含多个app的列表和MultiprogOS的image镜像加载到内存中,RustSBI(bootloader)完成基本的硬件初始化后,跳转到MultiprogOS起始位置
- MultiprogOS首先进行正常运行前的初始化工作,即建立栈空间和清零bss段,然后通过改进的 AppManager 内核模块从app列表中把所有app都加载到内存中,并按指定顺序让app在用户态一个接一个地执行。
- app在执行过程中,会通过系统调用的方式得到MultiprogOS提供的OS服务,如输出字符串等。
CoopOS
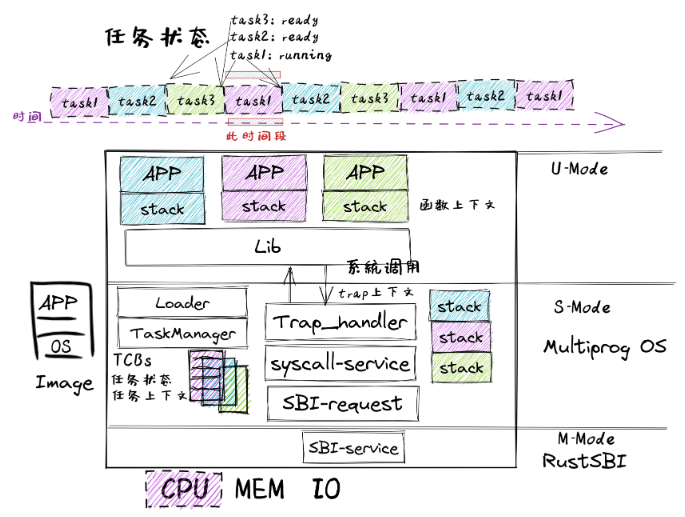
- CoopOS进一步改进了 AppManager 内核模块,把它拆分为负责加载应用的 Loader 内核模块和管理应用运行过程的 TaskManager 内核模块。
- TaskManager 通过 task 任务控制块来管理应用程序的执行过程,支持应用程序主动放弃 CPU 并切换到另一个应用继续执行,从而提高系统整体执行效率。
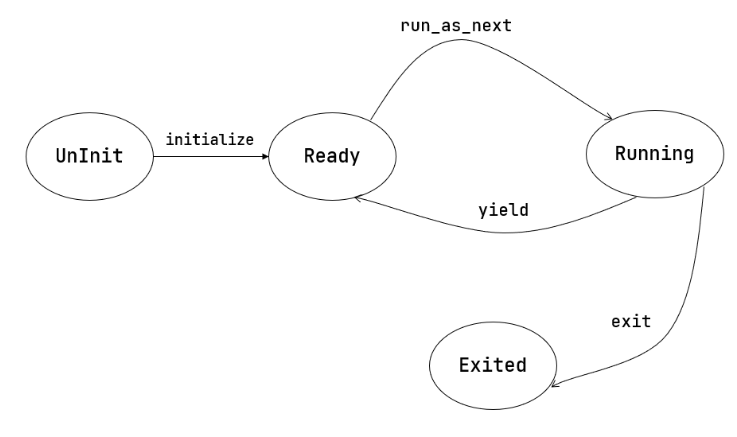
- 应用程序在运行时有自己所在的内存空间和栈,确保被切换时相关信息不会被其他应用破坏。如果当前应用程序正在运行,则该应用对应的任务处于运行(Running)状态;如果该应用主动放弃处理器,则该应用对应的任务处于就绪(Ready)状态。
- 操作系统进行任务切换时,需要把要暂停任务的上下文(即任务用到的通用寄存器)保存起来,把要继续执行的任务的上下文恢复为暂停前的内容,这样就能让不同的应用协同使用处理器了。
TimersharingOS
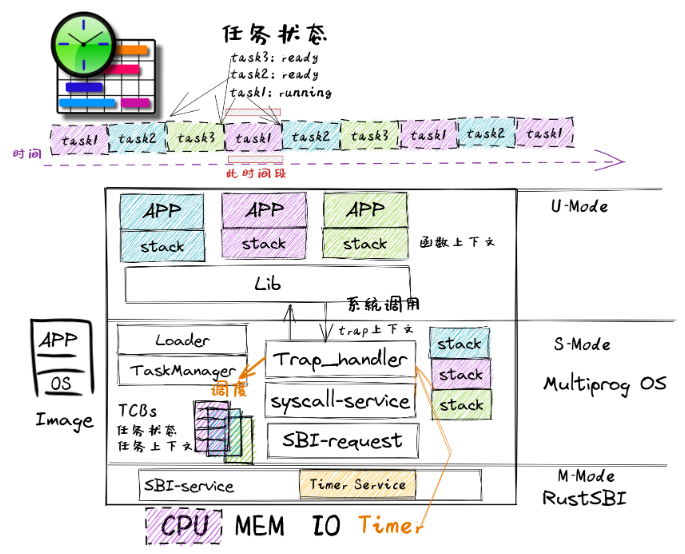
- TimesharingOS最大的变化是改进了 Trap_handler 内核模块,支持时钟中断,从而可以抢占应用的执行。
- 并通过进一步改进 TaskManager 内核模块,提供任务调度功能,这样可以在收到时钟中断后统计任务的使用时间片,如果任务的时间片用完后,则切换任务。从而可以公平和高效地分时执行多个应用,提高系统的整体效率。
多道程序放置与加载
放置
- 每个app的起始地址为
hex(base_address+step*app_id),实现起始地址的不同
# user/build.py |
加载
- 第i个应用加载到不同的物理地址上
APP_BASE_ADDRESS + i * APP_SIZE_LIMIT
// os/src/loader.rs |
任务切换
在内核中这种机制是在
__switch函数中实现的。 任务切换支持的场景是:一个应用在运行途中便会主动或被动交出 CPU 的使用权,此时它只能暂停执行,等到内核重新给它分配处理器资源之后才能恢复并继续执行。任务切换是来自两个不同应用在内核中的 Trap 控制流之间的切换。当一个应用 Trap 到 S 模式的操作系统内核中进行进一步处理(即进入了操作系统的 Trap 控制流)的时候,其 Trap 控制流可以调用一个特殊的
__switch函数。这个函数表面上就是一个普通的函数调用:在
__switch返回之后,将继续从调用该函数的位置继续向下执行。但是其间却隐藏着复杂的控制流切换过程。具体来说,调用__switch之后直到它返回前的这段时间,- 原 Trap 控制流 A 会先被暂停并被切换出去, CPU 转而运行另一个应用在内核中的 Trap 控制流 B 。
- 然后在某个合适的时机,原 Trap 控制流 A 才会从某一条 Trap 控制流 C (很有可能不是它之前切换到的 B )切换回来继续执行并最终返回。
- 不过,从实现的角度讲,
__switch函数和一个普通的函数之间的核心差别仅仅是它会 换栈 。
设计与实现
- 对于当前正在执行的任务的 Trap 控制流,我们用一个名为
current_task_cx_ptr的变量来保存放置当前任务上下文的地址;而用next_task_cx_ptr的变量来保存放置下一个要执行任务的上下文的地址。利用 C 语言的引用来描述的话就是:
TaskContext *current_task_cx_ptr = &tasks[current].task_cx; |
- 任务切换包含4个阶段
- 在 Trap 控制流 A 调用
__switch之前,A 的内核栈上只有 Trap 上下文和 Trap 处理函数的调用栈信息,而 B 是之前被切换出去的; - A 在 A 任务上下文空间在里面保存 CPU 当前的寄存器快照;
- 读取
next_task_cx_ptr指向的 B 任务上下文,根据 B 任务上下文保存的内容来恢复ra寄存器、s0~s11寄存器以及sp寄存器。只有这一步做完后,__switch才能做到一个函数跨两条控制流执行,即 通过换栈也就实现了控制流的切换 。 - 上一步寄存器恢复完成后,可以看到通过恢复
sp寄存器换到了任务 B 的内核栈上,进而实现了控制流的切换。这就是为什么__switch能做到一个函数跨两条控制流执行。此后,当 CPU 执行ret汇编伪指令完成__switch函数返回后,任务 B 可以从调用__switch的位置继续向下执行。
- 在 Trap 控制流 A 调用
- 从结果来看,我们看到 A 控制流 和 B 控制流的状态发生了互换, A 在保存任务上下文之后进入暂停状态,而 B 则恢复了上下文并在 CPU 上继续执行。
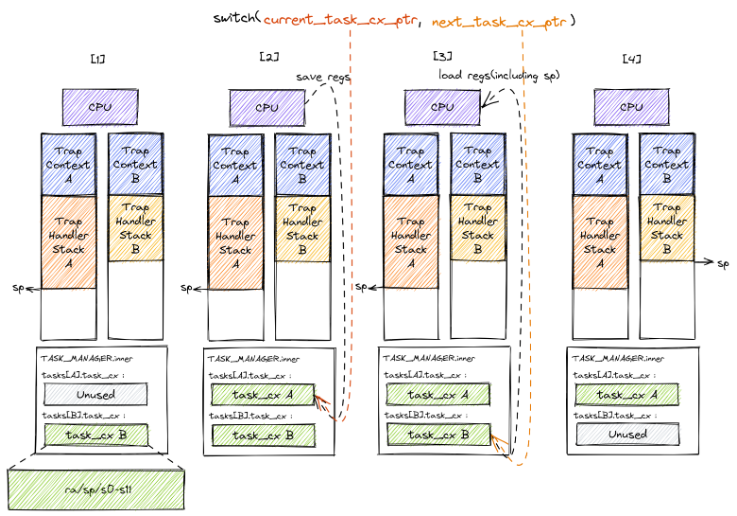
__switch实现
// os/src/task/switch.rs |
# os/src/task/switch.S |
TaskContext
// os/src/task/context.rs |
任务管理器
任务控制块(TCB)
// os/src/task/task.rs |
TaskContext::goto_restore将ra设置为__restore;因为切换任务时我们设定内核栈栈中包含__alltraps和trap_handler的栈帧- 当执行第一个程序时,我们需要向内核栈中压入一个
TrapContext// os/src/loader.rs
pub fn init_app_cx(app_id: usize) -> usize {
KERNEL_STACK[app_id].push_context(
TrapContext::app_init_context(get_base_i(app_id), USER_STACK[app_id].get_sp()),
)
}
// os/src/task/mod.rs
pub struct TaskManager {
num_app: usize,
inner: UPSafeCell<TaskManagerInner>,
}
struct TaskManagerInner {
tasks: [TaskControlBlock; MAX_APP_NUM],
current_task: usize,
}
lazy_static! {
pub static ref TASK_MANAGER: TaskManager = {
let num_app = get_num_app();
let mut tasks = [
TaskControlBlock {
task_cx: TaskContext::zero_init(),
task_status: TaskStatus::UnInit
};
MAX_APP_NUM
];
for i in 0..num_app {
tasks[i].task_cx = TaskContext::goto_restore(init_app_cx(i));
tasks[i].task_status = TaskStatus::Ready;
}
TaskManager {
num_app,
inner: unsafe { UPSafeCell::new(TaskManagerInner {
tasks,
current_task: 0,
})},
}
};
}
sys_yield和sys_exit系统调用
// os/src/syscall/process.rs |
suspend_current_and_run_next和exit_current_and_run_next均是切换当前Task的运行状态,切换到下一个应用
// os/src/task/mod.rs |
run_next_task
// os/src/task/mod.rs |
时间片轮转调度(Round-Robin)
时钟中断与计时器
- 在 RISC-V 64 架构上,该计数器保存在一个 64 位的 CSR
mtime中,我们无需担心它的溢出问题,在内核运行全程可以认为它是一直递增的。 - 另外一个 64 位的 CSR
mtimecmp的作用是:一旦计数器mtime的值超过了mtimecmp,就会触发一次时钟中断。这使得我们可以方便的通过设置mtimecmp的值来决定下一次时钟中断何时触发。 - 可惜的是,它们都是 M 特权级的 CSR ,而我们的内核处在 S 特权级,是不被允许直接访问它们的。好在运行在 M 特权级的 SEE (这里是RustSBI)已经预留了相应的接口,我们可以调用它们来间接实现计时器的控制
- 常数
CLOCK_FREQ是一个预先获取到的各平台不同的时钟频率,单位为赫兹,也就是一秒钟之内计数器的增量。
// os/src/timer.rs |
set_next_trigger设置下一个时钟中断get_time_us以微秒为单位返回当前计数器的值
// os/src/timer.rs |
抢占式调度
// os/src/trap/mod.rs |
- 我们只需在
trap_handler函数下新增一个条件分支跳转,当发现触发了一个 S 特权级时钟中断的时候,首先重新设置一个 10ms 的计时器,然后调用上一小节提到的suspend_current_and_run_next函数暂停当前应用并切换到下一个。 - 初始化设置
// os/src/main.rs |
sleep
- 目前在等待某些事件的时候仍然需要
yield,其中一个原因是为了节约 CPU 计算资源,另一个原因是当事件依赖于其他的应用的时候,由于只有一个 CPU,当前应用的等待可能永远不会结束。这种情况下需要先将它切换出去,使得其他的应用到达它所期待的状态并满足事件的生成条件,再切换回来。 - 这里我们先通过 yield 来优化 轮询 (Busy Loop) 过程带来的 CPU 资源浪费。在
03sleep这个应用中:
// user/src/bin/03sleep.rs |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 LZY的Code生活!
