Blogs ✍¶
Note
个人博客文章汇总,按时间倒序排列
Archives ¶
如果寻找不方便的话,不妨试试搜索或者前往 Tags 页面
面向 Agent 场景的长上下文边缘大模型推理优化研究报告,整理问题定义、系统主线、工程 trade-off 公式、实验假设与回改后的论文提纲。
Model Forward 瓶颈以及优化方法

本文将从为什么需要 speculative decoding 开始讲起,通过几篇论文来讲述现在投机采样演进的路线,以 SGLang 中 Eagle2 的实现作为 example 进行解析,并结合约束解码进行异步优化进行部分结果对比。
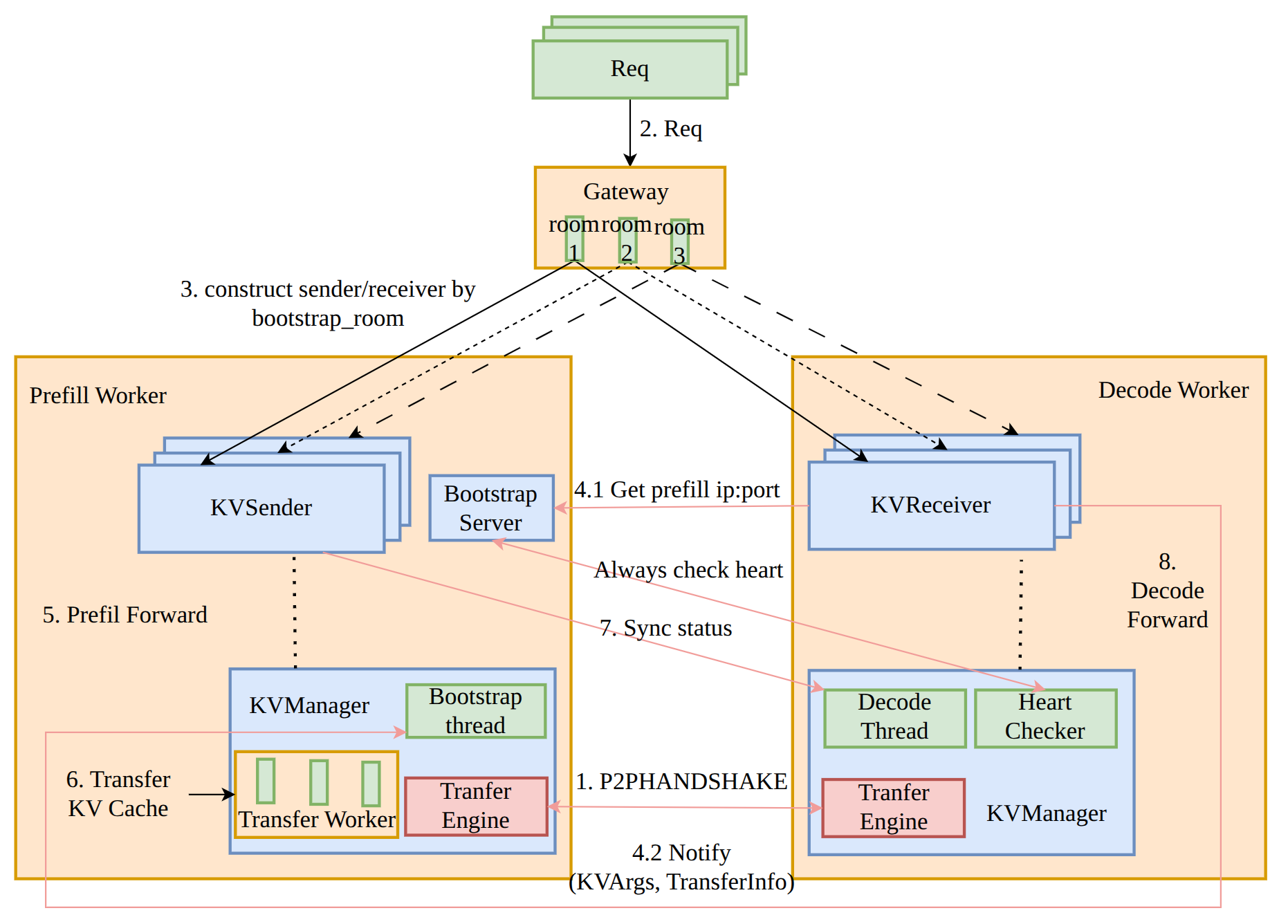
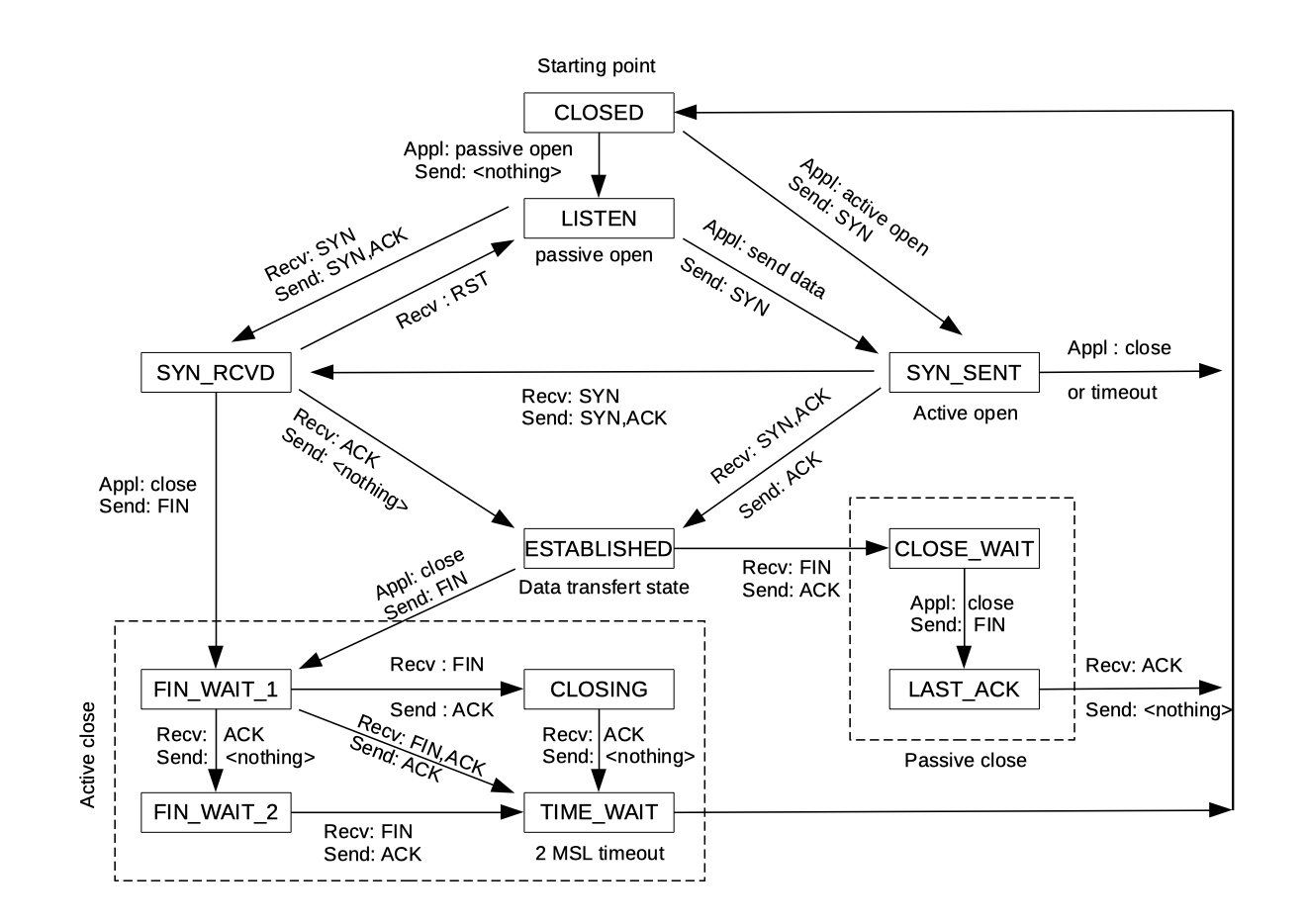
本文将从为什么需要 PD 分离开始讲起,通过几篇论文来讲述现在 PD 分离演进的路线,以 SGLang 中 PD 分离的实现作为 example 进行解析;由于笔者之前做过分布式相关的项目,将其中的状态机与 Raft 浅浅做了以下对比。
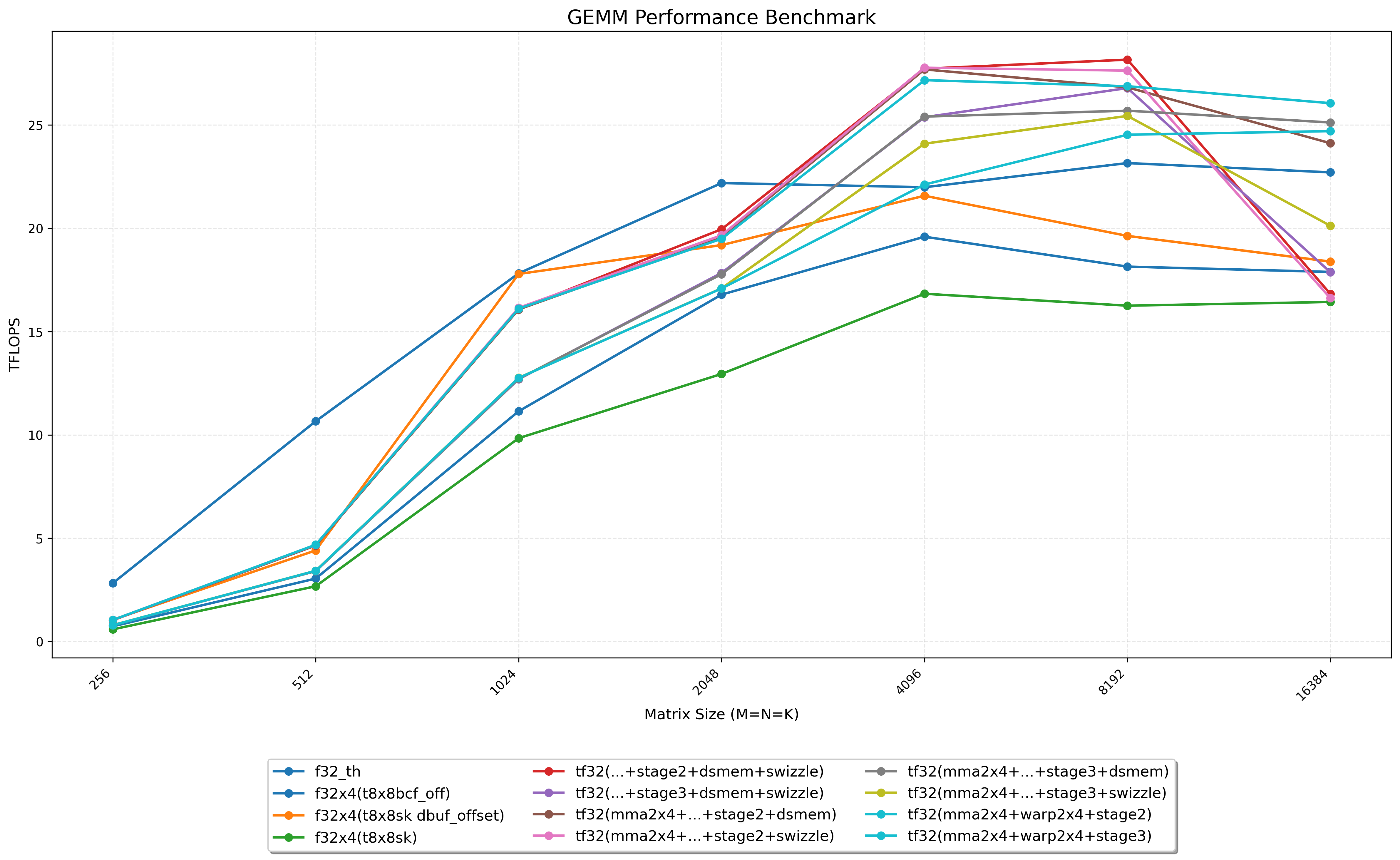
本文将从最 naive 的 GEMM 实现开始,使用 nsight compute 工具进行性能分析寻找瓶颈并一步步进行优化。通过这种方式来实践 CUDA 中的各种优化技巧,包括 Tiling、Free Bank Conflict、Double Buffer、wmma 指令优化等。
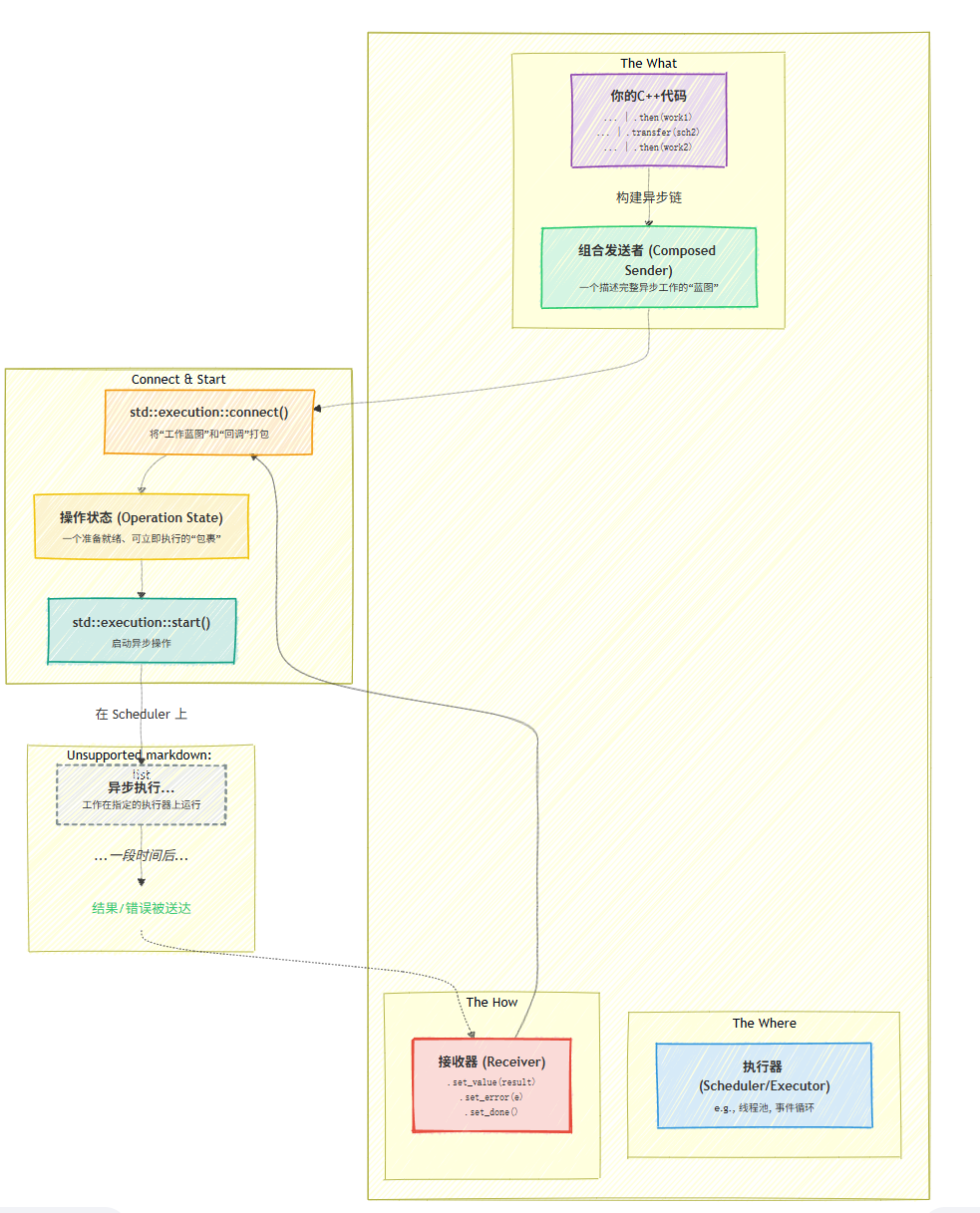
C++ 的异步执行方案历史演进,从标准库的 Future 和 Promise,到 Folly 的扩展封装,再到 C++26 中的 std::execution 和协程的结合,详细介绍了各个方案的原理和使用方法。
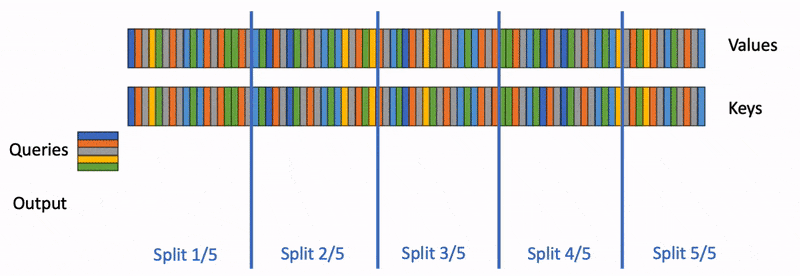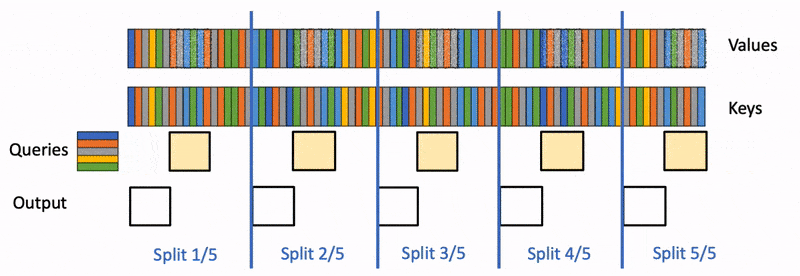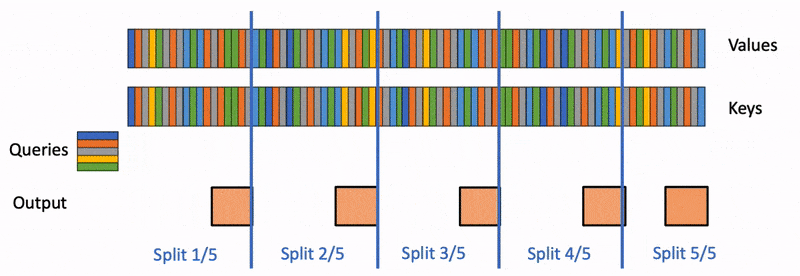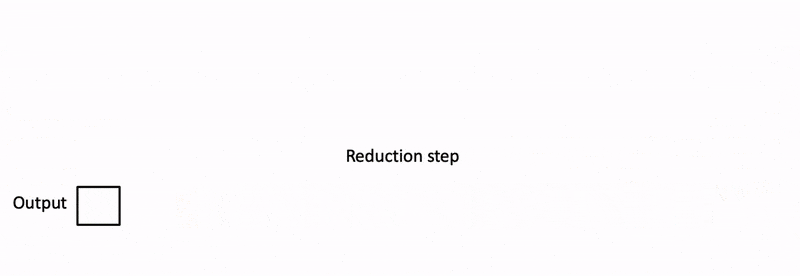
本文详细介绍 FlashAttention 的原理及其 v1-v3 版本的改进点,涵盖 Online Softmax、分块计算以及并行化优化等关键技术。
本文深入探讨 Page Attention 的实现细节,涵盖 GPU Tiling、矢量化访问、分层计算结构以及注意力内核的具体实现过程,帮助读者理解其高效计算注意力机制的原理。
本文介绍如何在使用 Bison 进行语法分析时进行冲突查看和调试,帮助开发者更好地理解和解决语法规则中的问题。
Bustub 通关指北,带你快速了解 Bustub 的核心组件和实现细节,包括 Parser、Planner、Optimizer、Executor 以及 Storage 模块的工作原理。
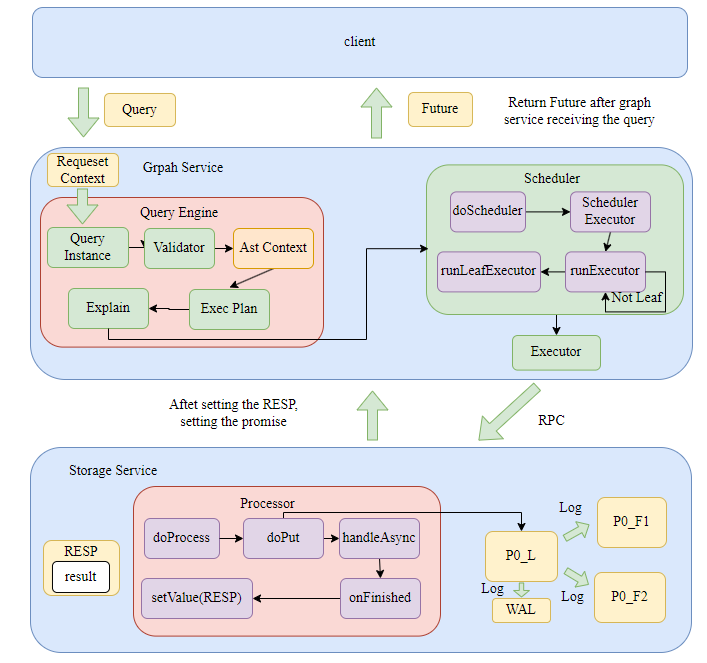
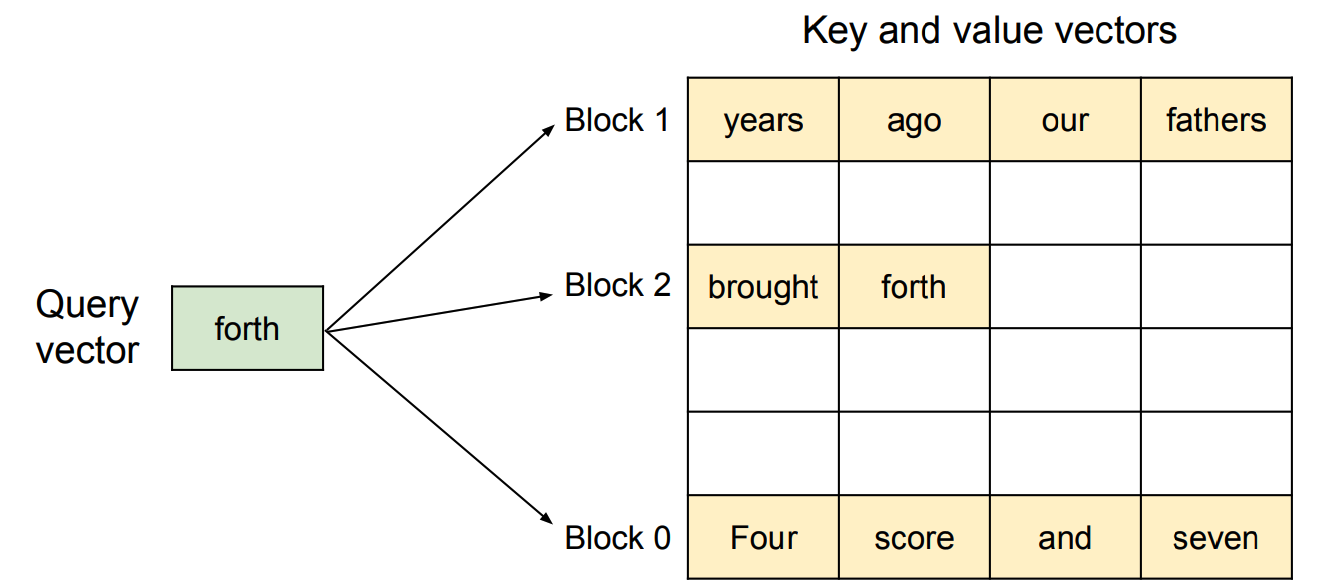
本篇文章介绍了 Nebula Graph 向量类型的设计与实现,涵盖向量数据类型的定义、序列化与反序列化方法,以及向量属性的存储结构和存储引擎的改动。
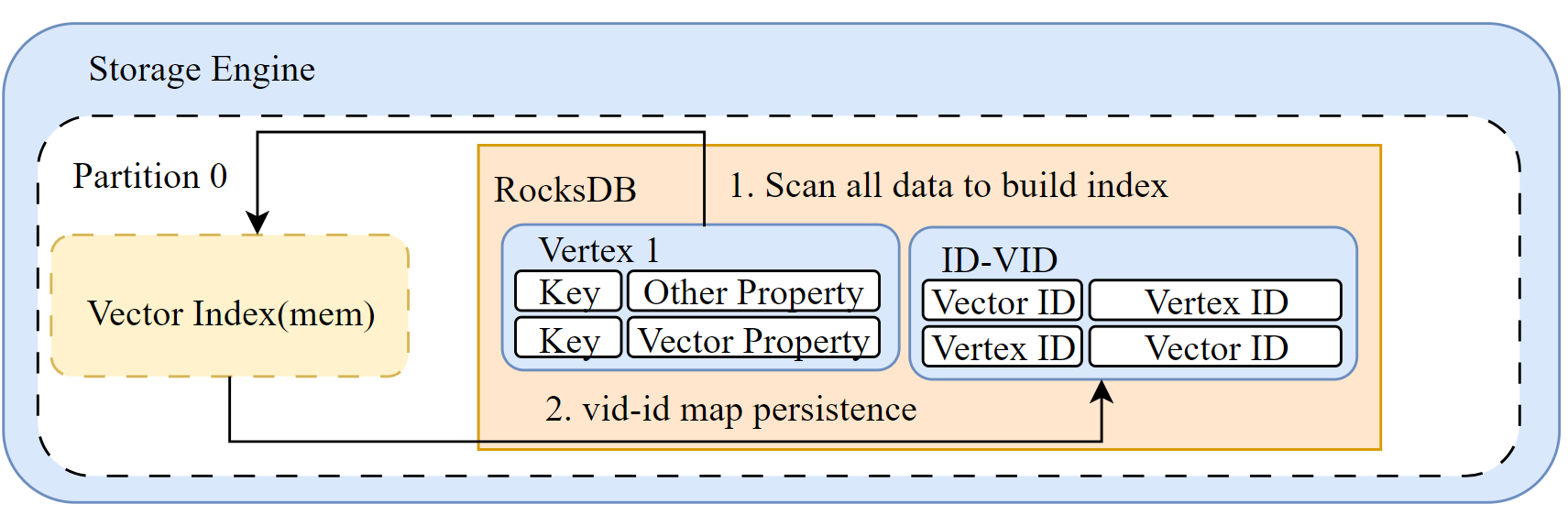
本篇主要介绍如何支持向量属性的 DDL 和 DML 语句,涵盖在 Nebula Graph 中添加 Vector 类型属性的实现细节。
本文探讨了 GPU 内存系统的演进路径,重点介绍了如何通过提升带宽利用率和隐藏延迟来优化 GPU 性能。涵盖了 Little's Law、ILP/DLP 并行扩展、异步内存加载以及启动延迟优化等关键技术。
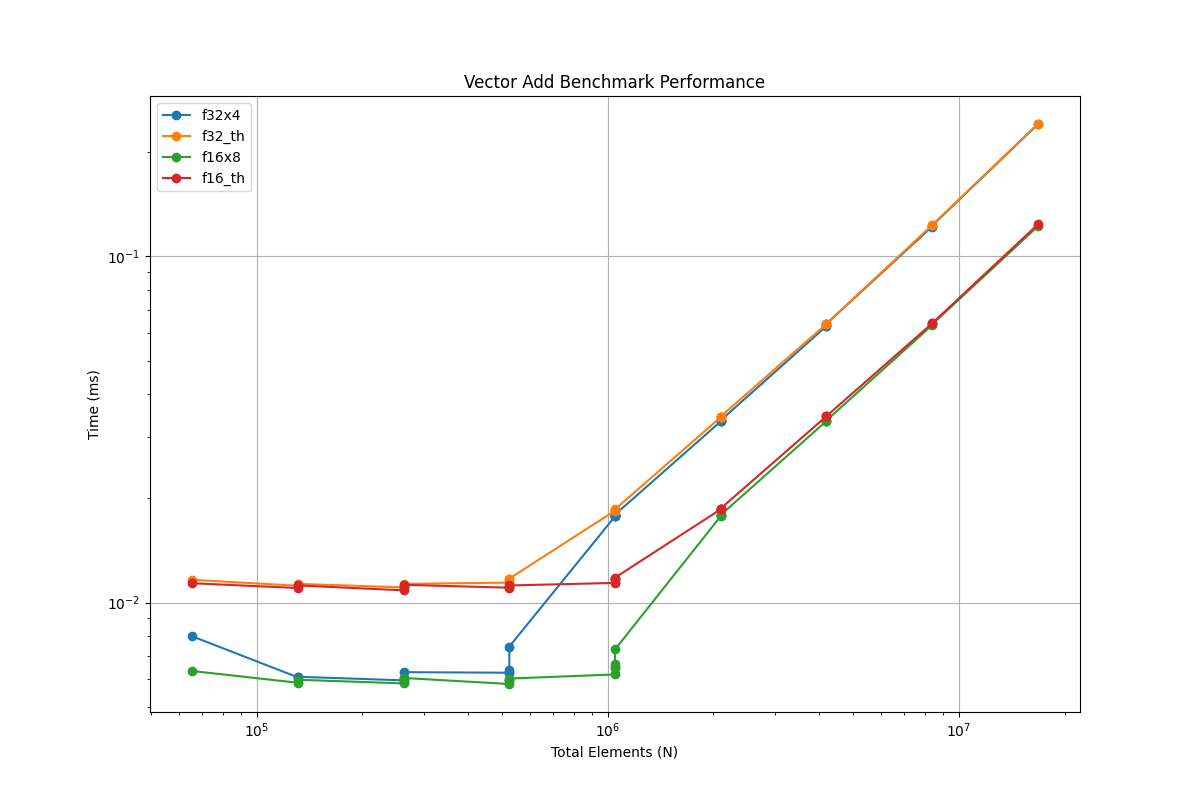
本文将通过一个简单的 CUDA Vector Add 例子,介绍如何使用 Nsight Compute 工具进行性能分析,并一步步进行优化。
在大规模语言模型(LLM)推理中,优化 CUDA 代码对于提升性能和效率至关重要。本文档介绍了一些关键的 CUDA 优化技术,帮助开发者更好地利用 GPU 资源进行 LLM 推理。
本文介绍了不同神经网络架构(如 MLP、CNN、RNN 和 Transformer)对计算模式的影响,探讨了这些模式如何映射到计算机系统资源,包括内存访问模式、计算特性、数据移动和资源利用。
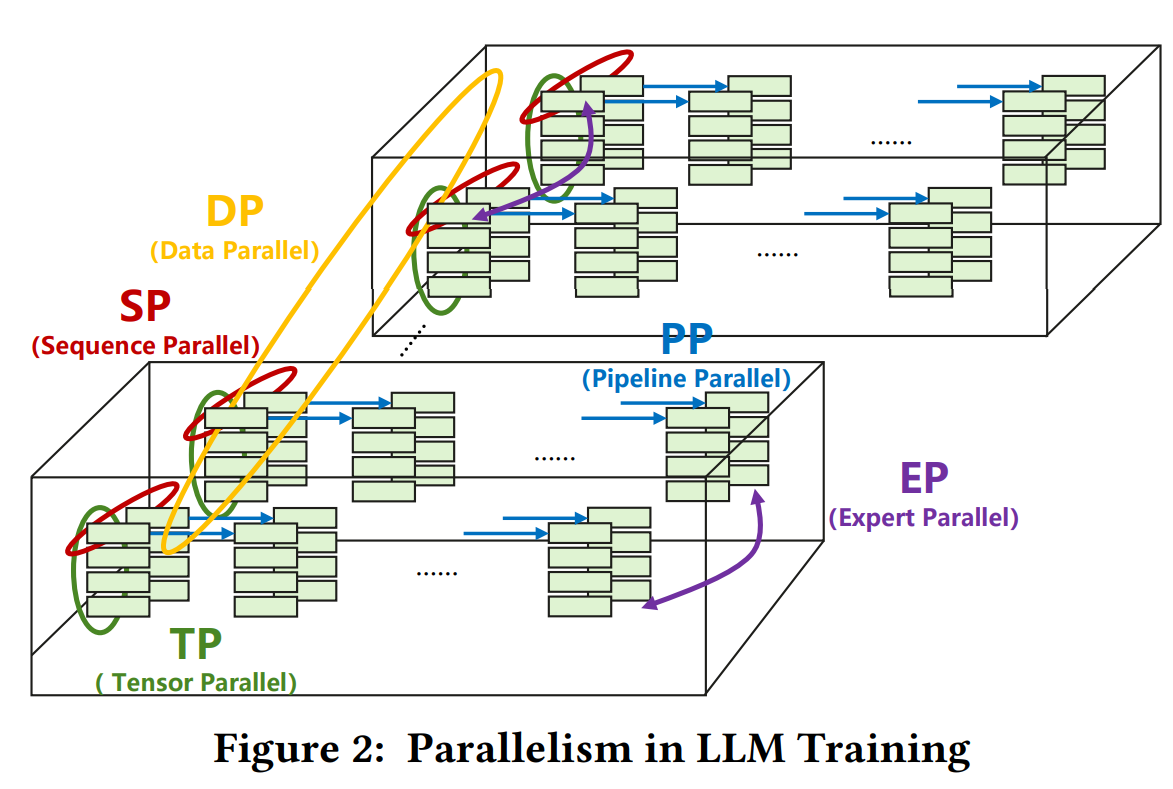
本文介绍了在基于 Transformer 的大规模语言模型(LLM)中常用的并行化技术,包括数据并行(DP)、张量并行(TP)、流水线并行(PP)、专家并行(EP)以及序列并行(SP)和上下文并行(CP)。通过 deepseek-V3 来进行具体分析这些并行化技术在训练和推理中的应用。
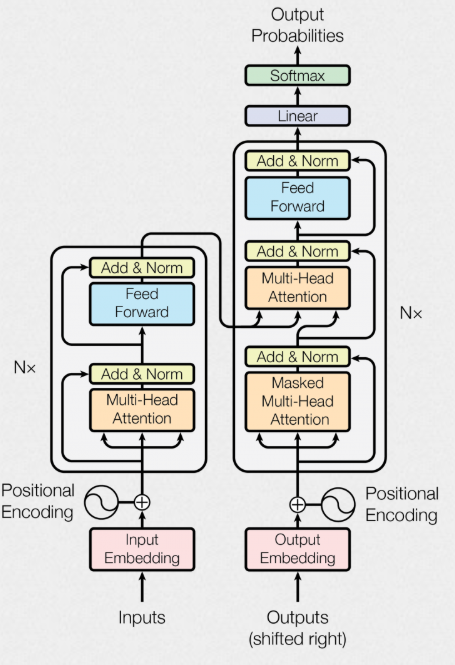
首先从概率论角度介绍语言生成模型最终训练目标然后介绍注意力机制(Attention)及其在 Transformer 架构中的应用,并详细解析 Transformer 的结构和工作流程。
本节主要介绍大模型训练中的并行化技术,涵盖数据并行、模型并行、流水线并行和张量并行等方法。我们将从 Transformer 的参数量、Flops 以及训练占用显存入手,分析为什么需要并行化技术,并介绍这些技术的基本原理。
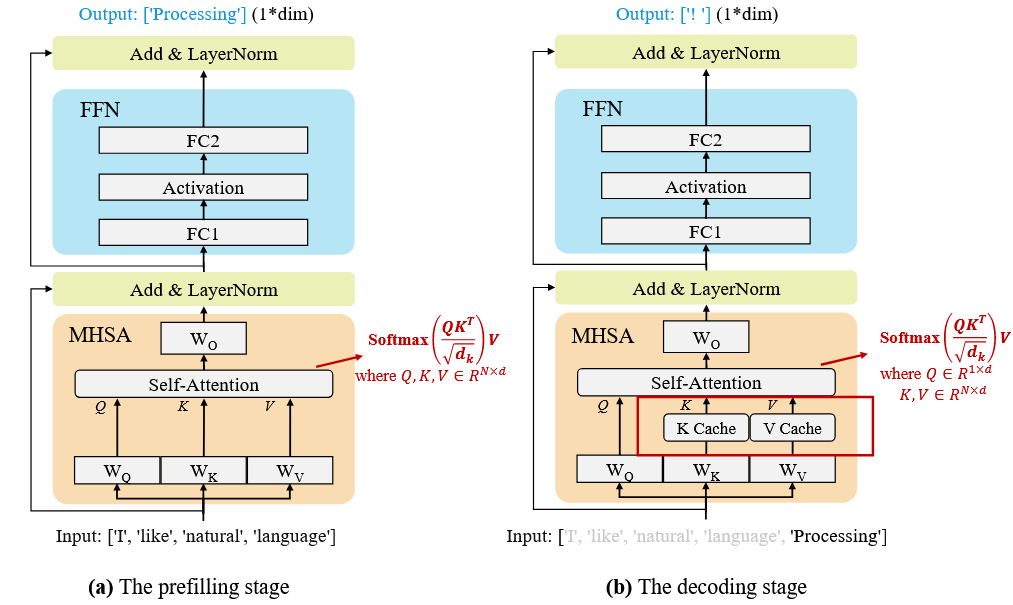
本章介绍基于 Transformer 架构的大规模语言模型(LLM),涵盖其核心组件如位置编码、注意力机制、归一化方法和前馈网络。
本文介绍 SGLang 中 Attention 层的数据并行(DP Attention)机制,涵盖其设计理念、实现细节及执行流程,旨在提升模型推理的效率和性能。
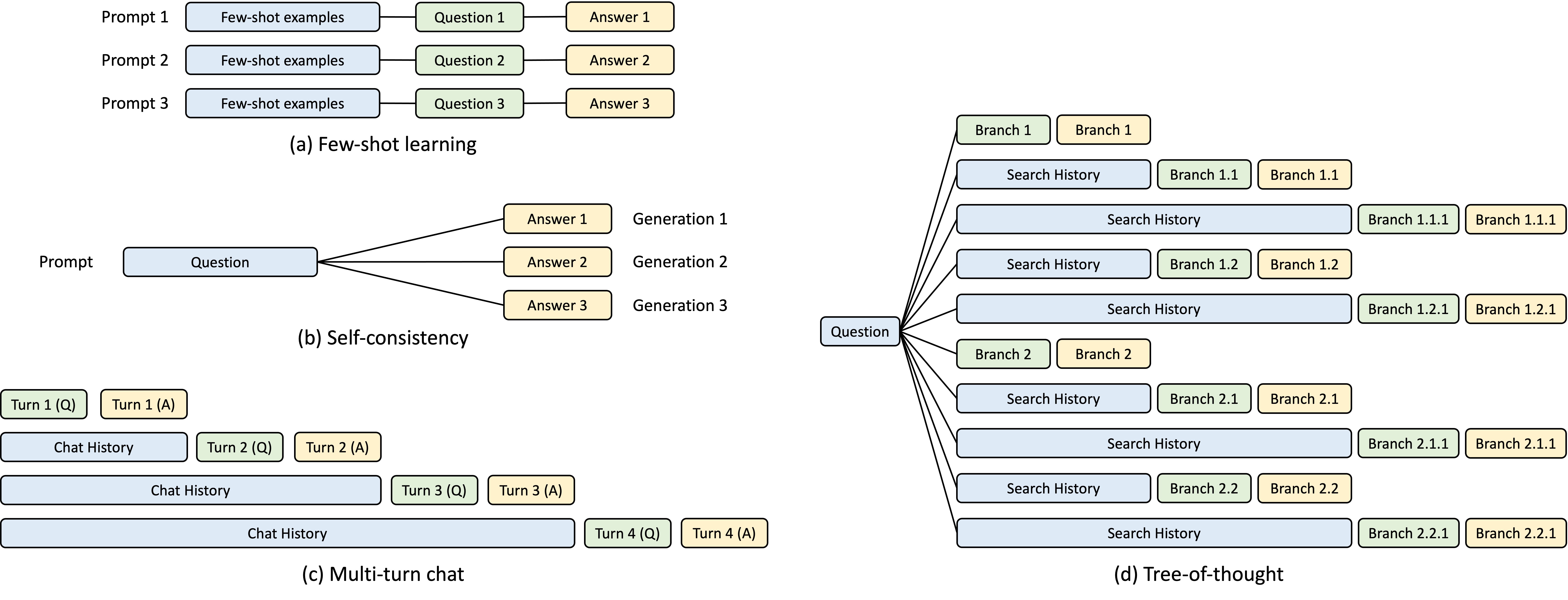
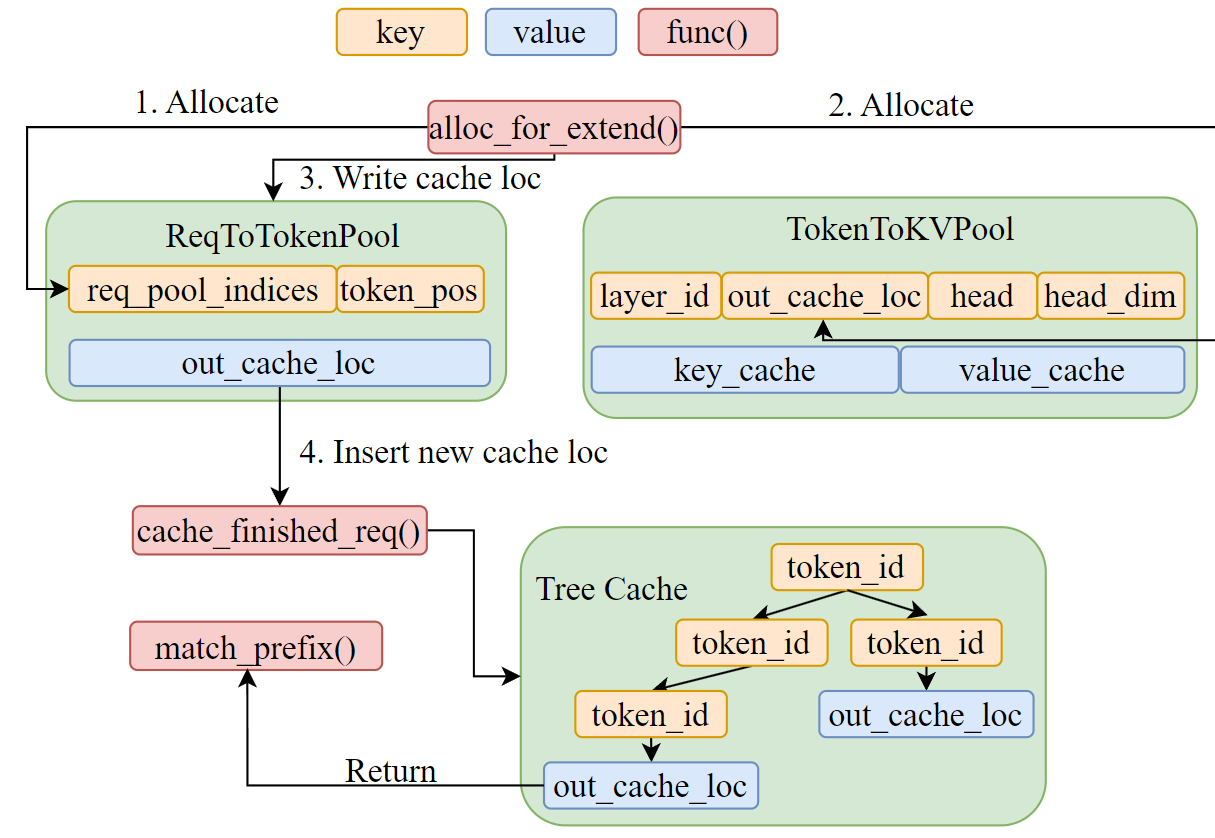
本文深入探讨 SGLang 中 RadixAttention 的实现细节,涵盖 Radix Tree 结构、前缀匹配、内存管理与驱逐策略,以及 Cache-Aware Scheduling 的工作原理。
本文将结合代码分析 SGLang Scheduler 的技术演进,介绍其核心数据结构和工作流程,帮助读者深入理解调度器的实现细节。
这里我们以 Qwen2 模型为例,开启 PP + TP 分析一下 SGLang 是如何实现模型推理的并行的
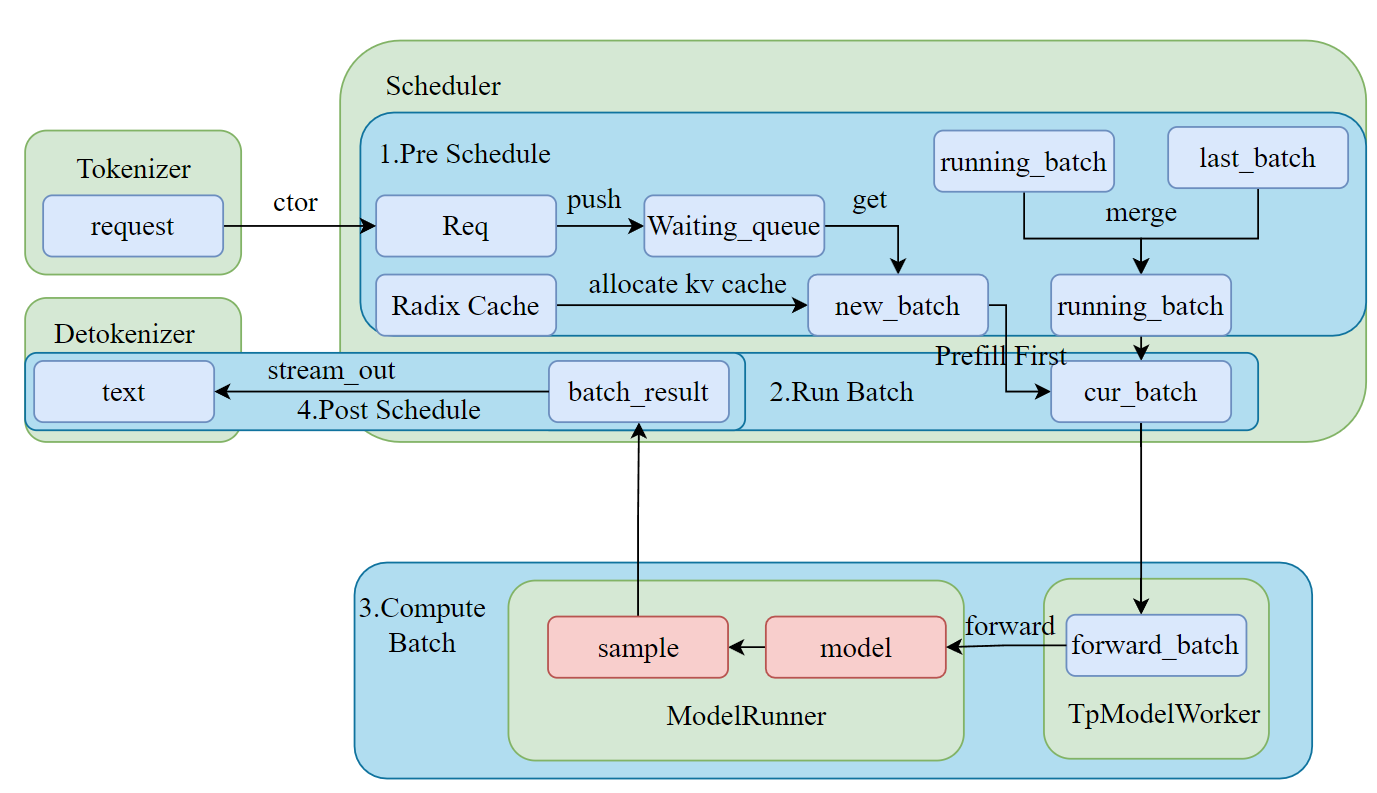
本文将介绍在 SGLang 中,一条请求从到达系统到最终完成的全过程,涵盖请求的接收、调度、执行以及结果返回等关键环节。
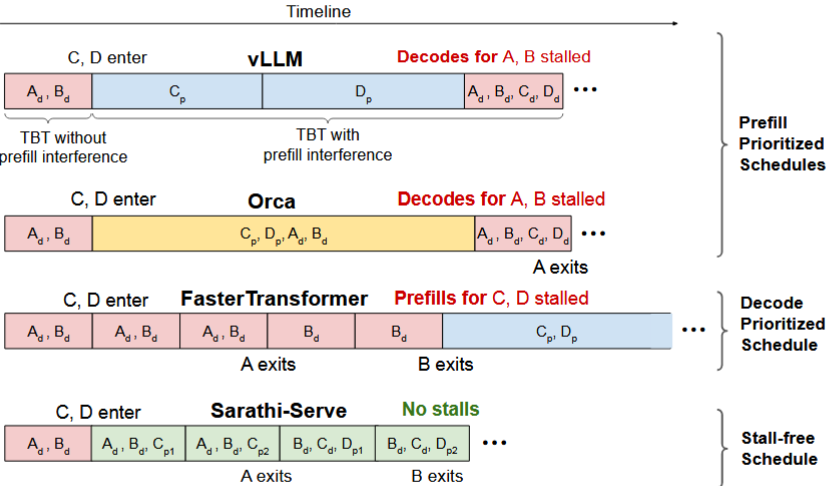
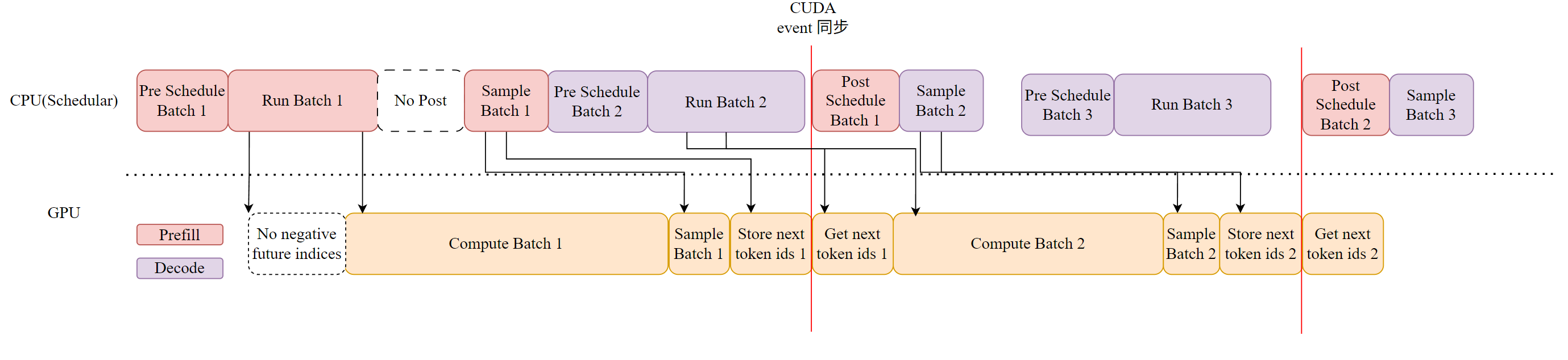
现在的大模型推理的框架基本都实现了 Continuous Batching,本文将从大模型推理服务为什么需要 Batching 开始,逐步讲解该领域的技术演进,包含调度层和计算层的相关优化技术。