DeepseekV4¶
约 4028 个字 151 行代码 7 张图片 预计阅读时间 22 分钟
模型架构¶
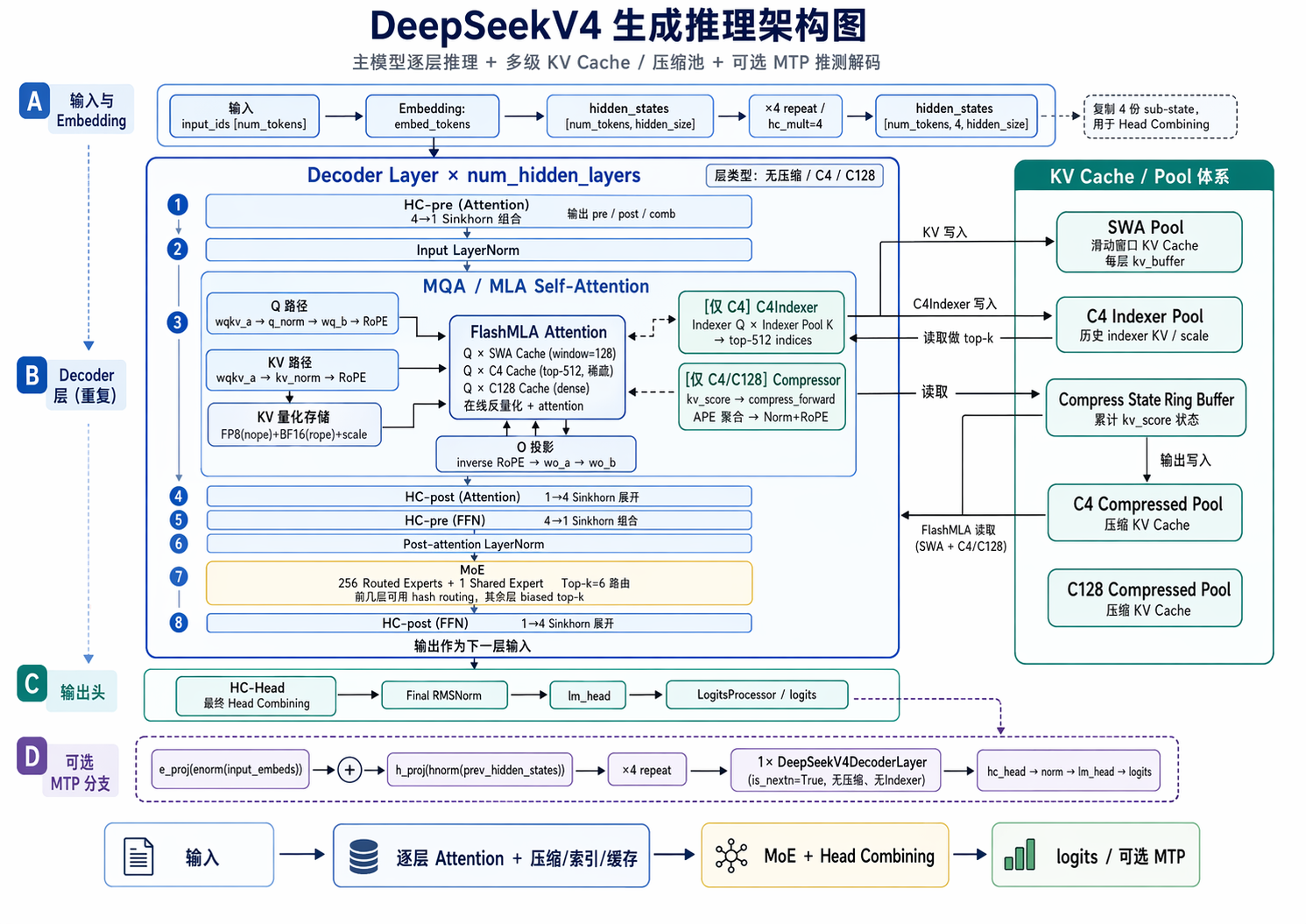
Attention¶
这里所有的 Attention 实际上都是 MLA 的方式计算,只是 KV 的压缩程度不同以及是否有 DSA 参与
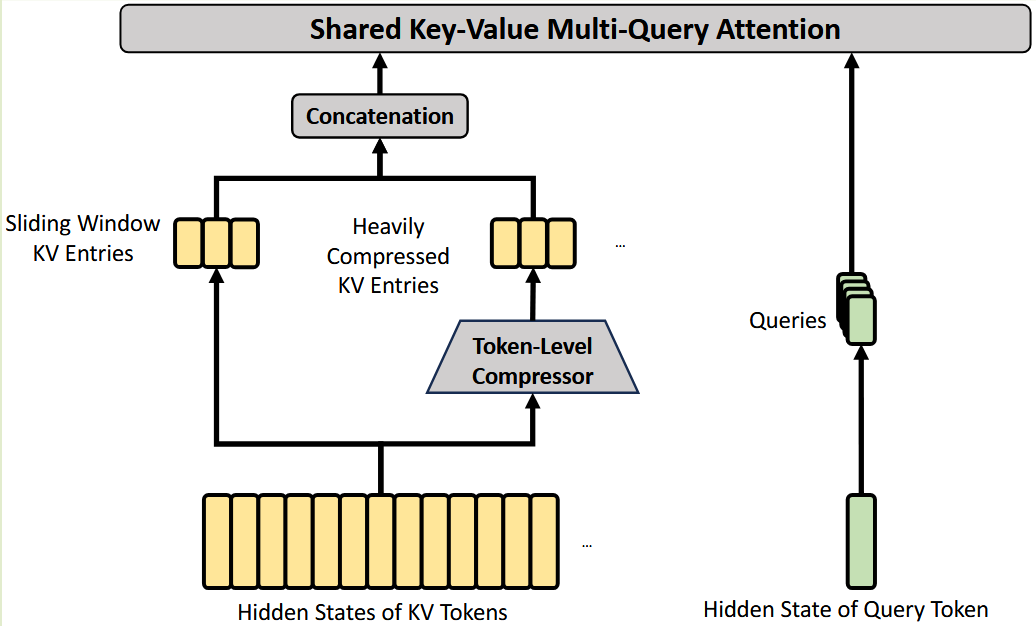
CSA(Compressed Sparse Attention)¶
- Compressed KV Entries:每 m 个 token 生成 1 个压缩 KV,但这个压缩 KV 实际会参考当前 block 的 m 个 token,以及前一个 block 的 m 个 token,一共 2m 个候选 token,然后用 learned softmax 权重加权求和(Overlap)
- DSA Strategy:对于每个 query,选择 top-k 的压缩 KV entry 进行 attention 计算,k 是一个超参数
- MQA:compressed kv entry 既是 K 又是 V,与 query 进行 MQA 计算
- Grouped Output Projection:先投影到c * n_h 太大,直接 \(R^{c n_h} -> R^d\) 的输出投影太贵,所以先按 head 分组,把每组从 \(R^{c n_h/g}\) 压到 \(R^{d_g}\),再把 g 个小向量拼起来投影回 \(R^d\)
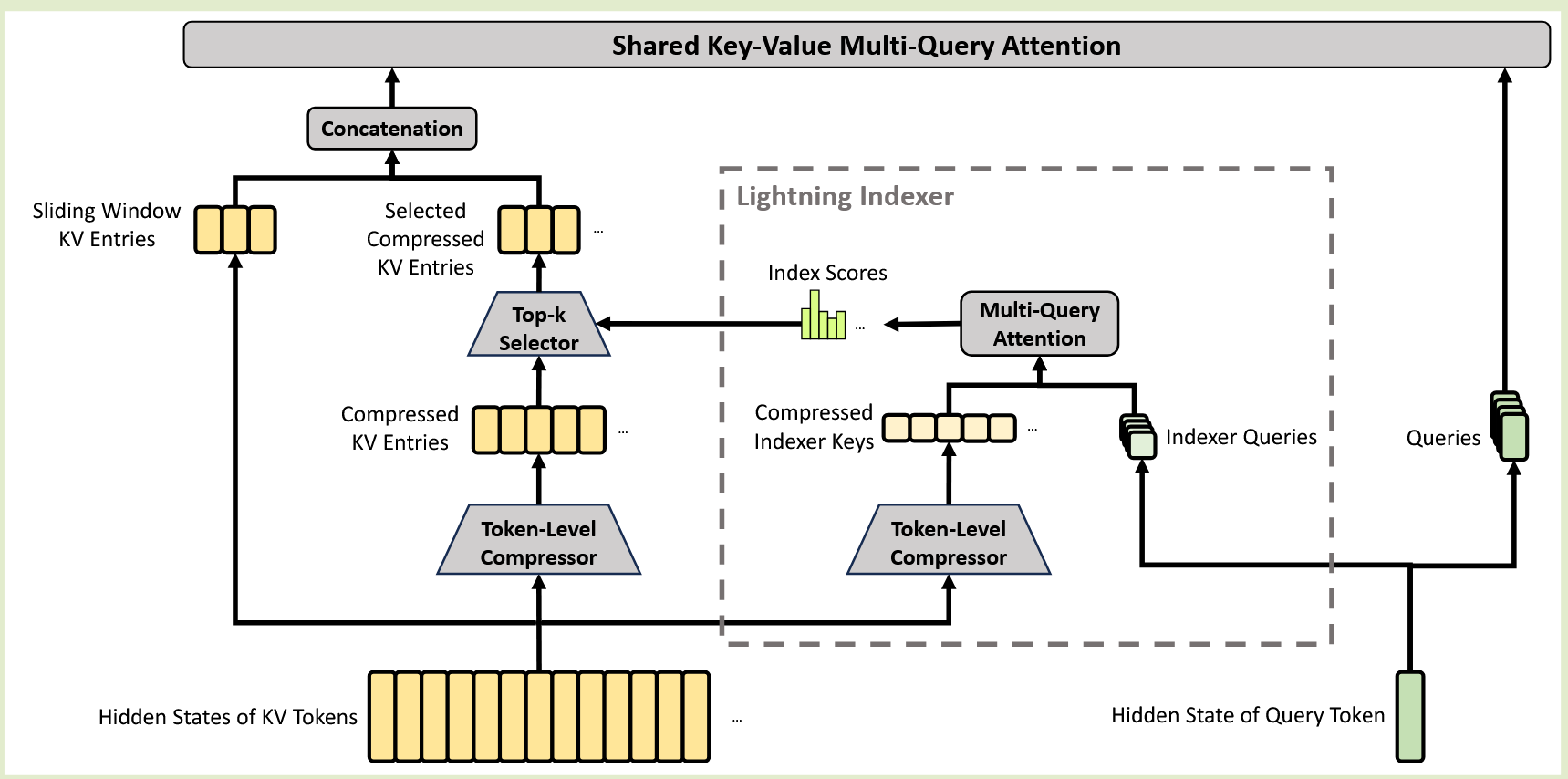
HCA(Heavily Compressed Attention)¶
-
Compressed KV Entries:每 m′ 个 token 压缩成一个 compressed KV,m′ 远大于 m,压缩程度更高,适用于更长的上下文
第 i 个 compressed KV 是第 i 个 block 内 m′ 个 token 的加权和,不在考虑前一个 block 的 token
-
Shared KV MQA:所有 query 共享同一组 compressed KV 进行 MQAttention 计算
-
Grouped Output Projection:同 CSA
Other Details¶
Partial RoPE¶
- 与 MLA 相同,只对最后 64 维度进行 RoPE
- Attention Output 施加 position -i 的 RoPE
Important
因为 compressed KV Entries 同时作为 K 和 V,实际上 V 不应该携带位置信息,所以这里对 attention output 施加 position -i 的 RoPE 来抵消掉 V 中的位置信息
Additional Branch of SWA¶
- Question:CSA 和 HCA 的 compressed KV 是按 block 生成的,可能会导致 query token 看不到同一个 compressed block 里已经过去的 token,这会损失非常重要的近邻信息
- Solution:增加一个 SWA 分支,合并 compressed KV + 最近 n_win 个未压缩 KV
Attention Sink¶
- Motivation:对于一些 query 来说,所有的 compressed KV 都不相关,如果强行让它们参与 attention 计算,可能会引入噪声,反而降低性能
- Attention Sink 允许:如果当前 head 觉得这些 KV 都没用,就把大部分概率质量给 sink。
因为 sink 的 value 近似为 0,所以该 head 输出可以接近 0。
推理流程¶
- Embedding:embed_tokens -> hidden_states * hc_mult(4)(通过 repeat 扩展)
- HC-Head:hc_head 把 4 个 sub-state 合并回 1 个 -> norm -> lm_head -> logits
- 每层 (DeepseekV4DecoderLayer):
- HC-pre (attn):Sinkhorn 归一化把 hidden 拆成 4 个 sub-state
- Input LayerNorm
- Attention (MQALayer):- Q/KV 计算(支持 fused wqkv_a)
- RoPE(Triton 融合 kernel)
- (可选) C4Indexer:计算 indexer Q,量化,top-k 选择
- (可选) Compressor:压缩 KV
- FlashMLA:SWA cache + C4/C128 cache 注意力
- O 投影
- HC-post (attn):合并残差
- HC-pre (FFN):再次 Sinkhorn 拆分
- Post-attention LayerNorm
- MoE:DeepseekV2MoE(hash-based / biased top-k 路由 + shared expert 融合)
- HC-post (FFN):合并残差
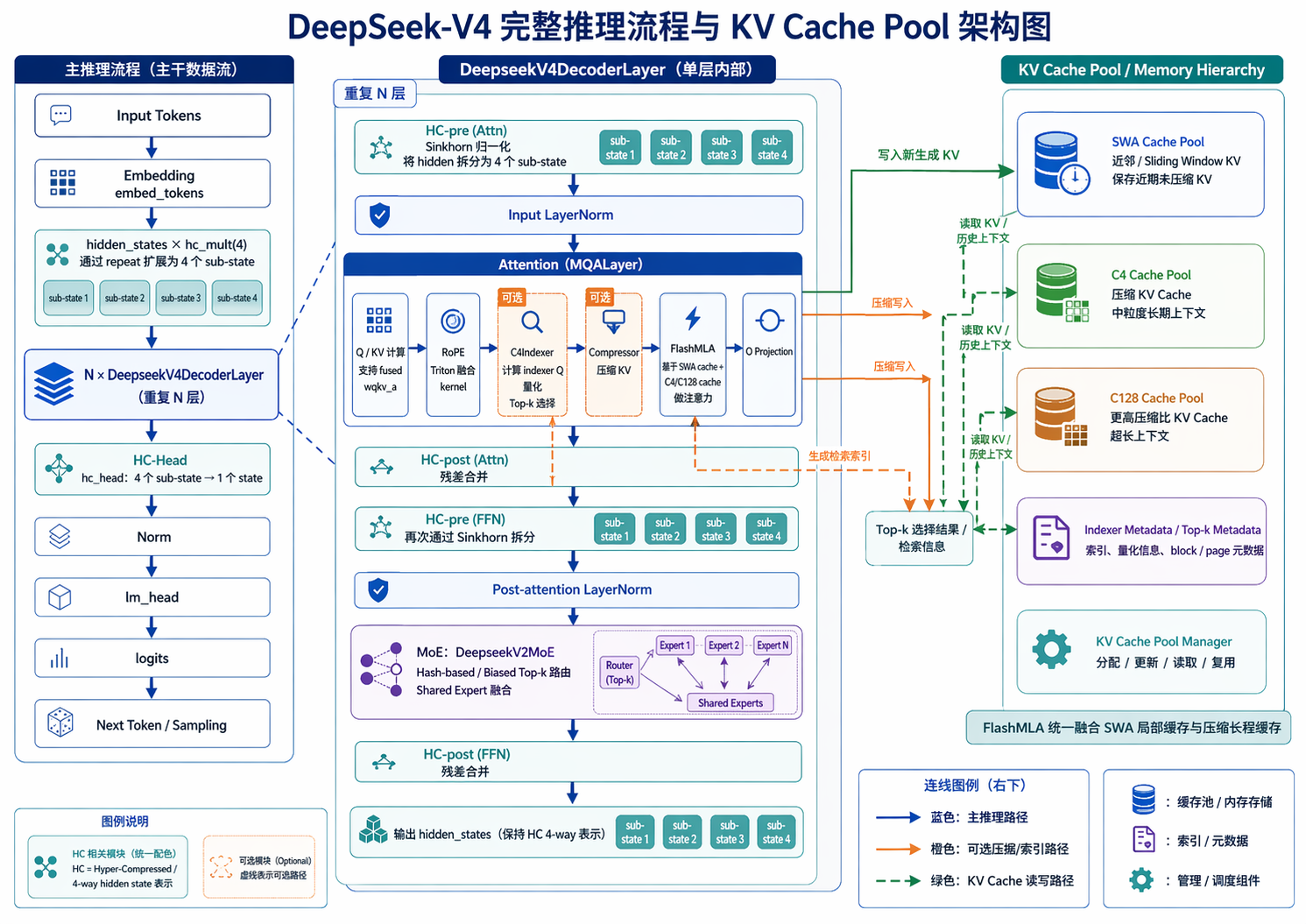
KV Cache Pool¶
SWA Pool¶
每个 token 的 完整 KV(未压缩)存入此池。所有层共享同一个 SWA 池(每个 layer_id 对应 kv_buffer[layer_id])。FlashMLA kernel 读取 SWA cache 时只看最近 window_size=128 个 token。
swa_kv_pool = DeepSeekV4SingleKVPool(
swa_size, swa_page_size=256, qk_nope_head_dim=448, qk_rope_head_dim=64,
layer_num=layer_num, # 所有层都在这里存一份
is_swa_pool=True, # 标记为 SWA 池
)
C4 Compressed Pool — 4:1 压缩 KV Cache¶
- 成员变量:与 SWA Pool 同构,区别是 page_size=64 且 layer_num 不同。
- 作用:只存 compress_ratio=4 的层的压缩后的 KV。每 4 个相邻 token 压缩为 1 个 token,然后量化存为相同的 NopeFp8RopeBf16Pack 格式。
- FlashMLA 读取:做 top-512 稀疏注意力,只取最近的 512 个压缩 token。
c4_kv_pool = DeepSeekV4SingleKVPool(
c4_size, c4_page_size=64, # page_size = 256/4 = 64
qk_nope_head_dim=448, qk_rope_head_dim=64,
layer_num=c4_layer_num, # 只给 compress_ratio==4 的层
)
C128 Compressed Pool — 128:1 压缩 KV Cache¶
- 成员变量:与 C4 池同构,page_size=2。
- 作用:存 compress_ratio=128 的层的压缩 KV。每 128 个 token 压缩为 1 个。
- FlashMLA 读取:做密集注意力(读所有压缩 token,不做稀疏选择)。
- 与 C4 的关键区别:
- C4 用重叠压缩(相邻 m 个 token 重叠(即 2m 个 token 计算),overlap=True, coff=2),取 top-512
- C128 用非重叠压缩(overlap=False, coff=1),全量 dense attention
C4 Indexer Pool — 索引器 KV Cache¶
- 存储格式:每 page 存
page_size * index_head_dim + page_size * num_scales_per_token * 4字节。与主 KV cache 不同,这里存的是 FP8 量化的 indexer K + float32 scale(通过 index_buf_accessor.SetKAndS 写入)。 - 作用:C4 层需要两步稀疏选择:
1. 先通过 C4Indexer 模块计算 indexer Q(index_head_dim=128),与 indexer pool 中的 K 做 fp8_paged_mqa_logits(top-k logits 计算)
2. 选出 top-k 的索引,再在 FlashMLA 中对 C4 压缩池做稀疏注意力
c4_indexer_kv_pool = DeepSeekV4IndexerPool(
c4_size, c4_page_size=64, index_head_dim=128,
layer_num=c4_layer_num,
)
Compress State Pool — 压缩中间状态 Ring Buffer¶
- KVAndScore: 是一个将 tensor 后半部分视为 score、前半部分视为 kv 的包装类。
- 作用: 压缩不是凭空从 hidden_state 直接算出最终 KV,而是分两步:
1. 第一步:linear_bf16_fp32(x, wkv_gate) 算出原始 kv_score(compress_forward 的输入)
2. 第二步:compress_forward 取 ring buffer 中累积的历史 kv_score + 当前 kv_score,配合 APE 做压缩- APE: Attention Position Embedding,控制每个 token 对 compressed output 的贡献
- Load 8 kv + 8 score entries from ring buffer (last ratio tokens)
- Add corresponding APE bias to each score: score[j][i] += bias[j][i]
- Safe softmax over 8 scores → attention weights
- Weighted sum Σ(kv[j] * weight[j]) → compressed output
ring buffer 存储的是未完成的压缩中间结果(kv + score),待到累积满 ratio 个 token 后才执行一次压缩输出。
Python# 每层两个 compress state pool:一个给主压缩,一个给 indexer 压缩 for ratio in compression_ratios: compress_state_pool = CompressStatePool( size, swa_page_size=256, ring_size=ring_size, overlap=(ratio==4), head_dim=512, ratio=ratio, ) if ratio == 4: indexer_compress_state_pool = CompressStatePool(...) # head_dim=128
- APE: Attention Position Embedding,控制每个 token 对 compressed output 的贡献
KV Cache 量化¶
整体来说,DeepSeek V4 有 三类 KV cache 存储,每类有不同的量化策略:
| 存储类型 | 压缩率 | 量化方式 | 存储格式 |
|---|---|---|---|
| SWA KV Cache (dense attention) | ratio=0, 不压缩 | FP8 nope + BF16 rope + UE8M0 scale | NopeFp8RopeBf16Pack |
| C4 压缩 KV Cache | ratio=4, 重叠滑动窗口 | FP8 nope + BF16 rope + UE8M0 scale | NopeFp8RopeBf16Pack |
| C128 压缩 KV Cache | ratio=128, 非重叠滑动窗口 | FP8 nope + BF16 rope + UE8M0 scale | NopeFp8RopeBf16Pack |
| C4 Indexer K Cache | ratio=4 only | FP8 + per-tile FP32 scale (act_quant) | index_k_fp8 + index_k_scale |
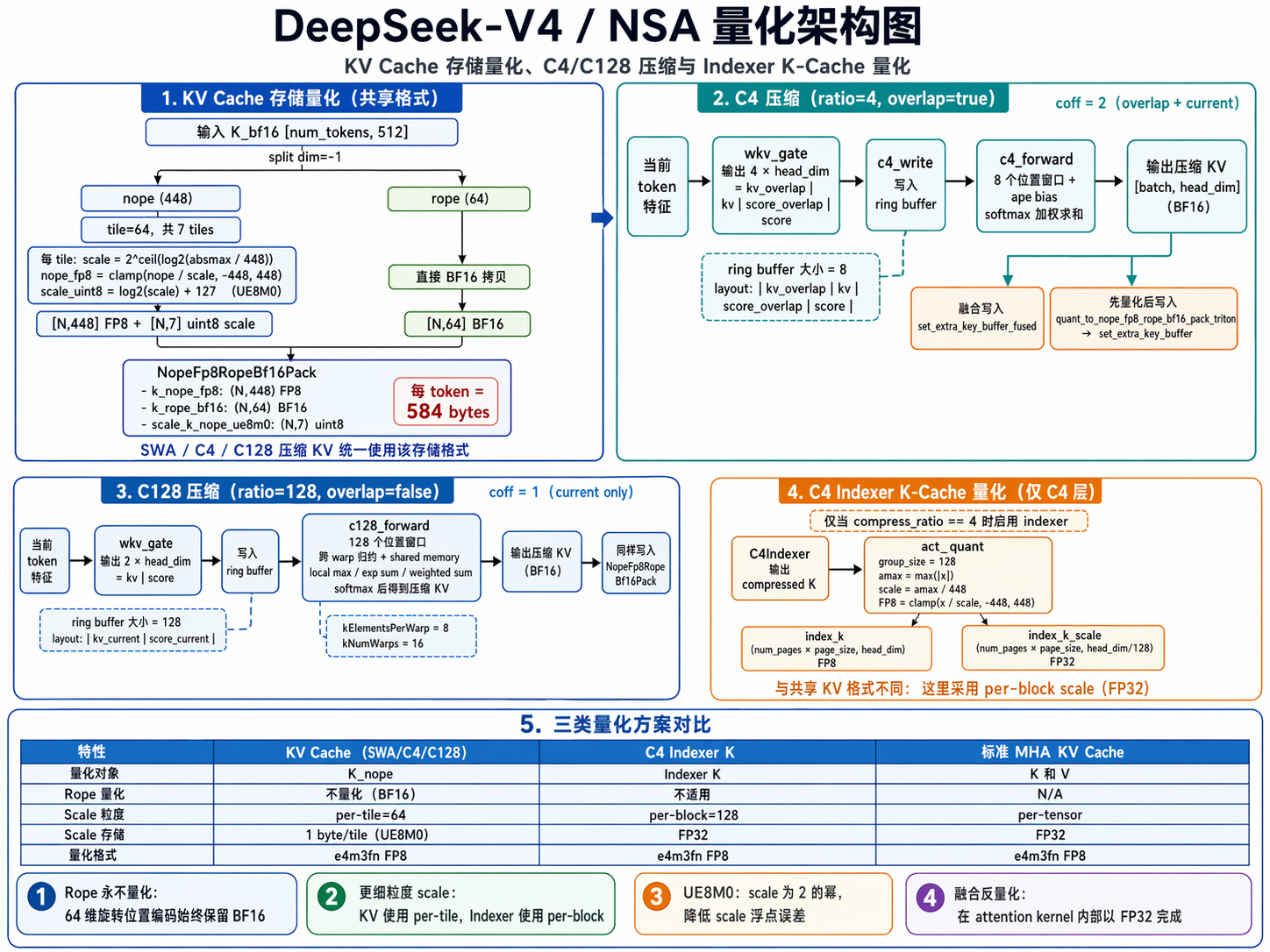
存储格式(NopeFp8RopeBf16Pack)¶
这是所有压缩模式共享的 KV 存储格式。
- Nope 部分:FP8 量化的 K/V,448 维(7 个 head,每个 head 64 维)
- RoPE 部分:BF16 量化的 RoPE 位置编码,64 维
- Scale 部分:UE8M0 量化的 scale,用于从 Nope 的 uint8 还原到 float32,7 个 head 每个 head 1 个 scale
@dataclass
class NopeFp8RopeBf16Pack:
k_nope_fp8: torch.Tensor # (N, 448) fp8
k_rope_bf16: torch.Tensor # (N, 64) bf16
scale_k_nope_ue8m0: torch.Tensor # (N, 7) uint8
每token存储: 448×1 + 64×2 + 7×1 + 1(pad) = 584 bytes
模型层:Compressor 如何产生 kv_score¶
每个 MQALayer 中:
self.ratio = 4
self.overlap = True # ← C4 独有
self.coff = 2
# deepseek_v4.py:198-205
# wkv_gate 是一个无bias的线性层:
self.wkv_gate = ReplicatedLinear(self.dim, 2 * coff * self.head_dim)
# C4: dim → 2*2*head_dim = 4*head_dim
# C128: dim → 2*1*head_dim = 2*head_dim
# ape是可学习的绝对位置偏置:
self.ape = nn.Parameter(torch.empty(self.ratio, coff * self.head_dim))
# C4: [4, 2*head_dim] → 展开后 [8, head_dim]
# C128: [128, 1*head_dim] → 展开后 [128, head_dim]
forward 流程:
def forward(self, x, forward_batch):
kv_score = linear_bf16_fp32(x, self.wkv_gate.weight)
# C4: kv_score.shape = [num_tokens, 4 * head_dim]
# C128: kv_score.shape = [num_tokens, 2 * head_dim]
return self.compress_fused(kv_score, forward_batch)
C4 压缩的 CUDA Kernel¶
数据布局¶
C4 每个 token 产生 4 段,每段 head_dim 个元素:
kv_score_input[t] = [kv_overlap | kv_current | score_overlap | score_current]
|← head_dim →|← head_dim →|← head_dim →|← head_dim →|
offset 0 offset hd offset 2hd offset 3hd
Ring buffer 存储最后 8 个 token 的这 4 段:
写入 ring buffer¶
Decode 时每个新 token 都写,只有当 seq_len % 4 == 0 时才做 c4_forward 压缩。
// 每个 token 到达时:把它写到 ring buffer 的 (seq_len+7)%8 位置
template <typename T>
SGL_DEVICE void c4_write(T* kv_score_buf, const T* kv_score_src,
int64_t head_dim, int32_t write_pos) {
kv_score_buf += write_pos * (head_dim * 4); // 定位到该位置
for (int i = 0; i < 4; ++i) {
kv_score[i] = gmem.load(kv_score_src + head_dim * i); // 加载4段
gmem.store(kv_score_buf + head_dim * i, kv_score[i]); // 写入
}
}
压缩计算¶
核心流程分两步:
- Step 1: 加载 8 个位置的 KV 和 Score,每个 token \(t\) 通过 wkv_gate 生成:
$$
\begin{aligned}
\mathbf{kv}^{\text{overlap}}t &= \text{wkv_gate}(x_t)[0:H] \
\mathbf{kv}^{\text{current}}_t &= \text{wkv_gate}(x_t)[H:2H] \
s^{\text{overlap}}_t &= \text{wkv_gate}(x_t)[2H:3H] \
s^{\text{current}}_t &= \text{wkv_gate}(x_t)[3H:4H]
\end{aligned}
$$
其中 \(H = \text{head\_dim}\)。
- 边界条件:当 seq_len == 4(第一个 block),overlap 位置用 kv=0, score=-1e9,确保它们不影响 softmax。
- Step 2: Safe Online Softmax + 加权求和
$$
\begin{aligned}
\tilde{k}v[d] &= \frac{\sum}^{7} \exp(\tilde{sj[d]) \cdot \tilde{k}v_j[d]}{\sum}^{7} \exp(\tilde{sj[d])} \[8pt]
\text{其中 } \tilde{k}v_j &= \begin{cases}
\mathbf{kv}^{\text{overlap}} & j=0,1,2,3 \
\mathbf{kv}^{\text{current}}{t-7+j} & j=4,5,6,7
\end{cases} \[4pt]
\tilde{s}_j &= \begin{cases}
s^{\text{overlap}}} + \mathbf{ape{j} & j=0,1,2,3 \
s^{\text{current}} & j=4,5,6,7} + \mathbf{ape}_{j
\end{cases}
\end{aligned}
$$
本质: 这是一个 去除 Q 的线性注意力(Linear Attention without Query)。Score 由网络自行学习(通过 wkv_gate + ape),不依赖于当前 token 的 Query。Q 只在后续的 MQA attention 中才参与计算。
为什么 overlap:
- 如果没有 overlap,两个相邻的压缩 block 之间会存在 information gap
- 有 overlap 时,block N 的压缩窗口包含了 block N-1 的最后 4 个 token,保证信息连续
- kv_overlap 和 kv_current 使用不同的投影参数(wkv_gate 的不同输出维度),允许它们表达不同类型的上下文关系
- score_overlap 和 score_current 同理,网络可以学习对历史 token 和当前 token 赋予不同的注意力权重
C128 压缩的 CUDA Kernel¶
数据布局¶
C128 每个 token 仅 2 段:
Ring buffer:
写入 ring buffer¶
- C128 kernel 使用 16 个 warp 协作(因为 128/L=32),只有最后一个 warp 负责写入,其他 warp 等待。
- 对于 window_size = 128,head_dim 的每个元素 \(d\):
$$
\begin{aligned}
\mathbf{kv}_t &= \text{wkv_gate}(x_t)[0:H] \
s_t &= \text{wkv_gate}(x_t)[H:2H]
\end{aligned}
$$
压缩计算¶
- Phase 1: 每个 warp 独立处理 8 个位置
(每 128 个 token 触发一次):
$$
\tilde{kv}[d] = \frac{\sum_{j=0}^{127} \exp(s_{t-127+j}[d] + \mathbf{ape}j[d]) \cdot \mathbf{kv}}[d]}{\sum_{j=0}^{127} \exp(s_{t-127+j}[d] + \mathbf{ape}_j[d])
$$
C++// 第 w 个 warp 负责位置 [w*8, w*8+7]: const int32_t warp_offset = warp_id * kElementsPerWarp; // 每个warp处理8个位置 for (int32_t i = 0; i < kElementsPerWarp; ++i) { // i=0..7 const int32_t j = i + warp_offset; // 全局位置索引 if (j < window_len) { src = kv_score_buf + j * element_size; // 从ring buffer加载 } else { src = kv_score_src + (j - 127) * element_size; // ragged tail } kv[i] = gmem.load(src); score[i] = gmem.load(src + score_offset); } // 局部 softmax(warp内) for (int32_t i = 0; i < kTileElements; ++i) { // 遍历 head_dim 元素 for (int32_t j = 0; j < 8; ++j) { score_fp32[j] = score[j][i] + bias[j][i]; // + ape } float max_value = max(score_fp32[0..7]); float sum_product = 0, sum_exp = 0; for (int32_t j = 0; j < 8; ++j) { float exp_score = expf(score_fp32[j] - max_value); sum_product += kv[j][i] * exp_score; sum_exp += exp_score; } // 存储到 shared memory tmp_val_max[i] = max_value; tmp_exp_sum[i] = sum_exp; tmp_product[i] = sum_product; } s_local_val_max(warp_id, lane_id) = tmp_val_max; s_local_exp_sum(warp_id, lane_id) = tmp_exp_sum; s_local_product(warp_id, lane_id) = tmp_product; __syncthreads(); -
Phase 2: 跨 warp 全局归约
C++//16 个 warp 各自有局部的 (val_max, exp_sum, product),现在需要做全局 safe softmax 归约: for (uint32_t i = 0; i < kIteration; ++i) { // 读取第 local_warp_id 个 warp 的局部结果 float local_val_max = s_local_val_max(local_warp_id, local_lane_id, local_tile_id); float local_exp_sum = s_local_exp_sum(local_warp_id, local_lane_id, local_tile_id); float local_product = s_local_product(local_warp_id, local_lane_id, local_tile_id); // 跨16个warp做 safe softmax 归约 float global_val_max = warp::reduce_max<16>(local_val_max); float rescale = expf(local_val_max - global_val_max); float global_exp = warp::reduce_sum<16>(local_exp_sum * rescale); float final_scale = rescale / global_exp; float global_prod = warp::reduce_sum<16>(local_product * final_scale); kv_out[local_elem_id] = (OutFloat)global_prod; } -
C4 有两种 kv/score 类型(overlap vs current),C128 只有一种
为什么这样设计 KV 压缩?¶
线性注意力的压缩 (Linear Attention Compression)¶
传统的 cross-attention 压缩需要 Q(而 Q 需要到当前 token 才知道)。DeepSeek V4 的压缩使用 score-based linear attention:
- 常规 attention: \(\text{output} = \text{softmax}(QK^T) \cdot V\)
- 压缩用 score attention: \(\tilde{kv} = \text{softmax}(s + \text{ape}) \cdot \mathbf{kv}\)
其中 \(s\) 是 wkv_gate 直接从 \(x_t\) 投影出来的标量 score,不依赖 Q。这意味着:
- 压缩可以在 token 到达时立即完成(不需要等 Q)
- 压缩后的结果是一个固定大小的吸引子状态(attractor state),可以被后续任何 Q 查询
- wkv_gate 学习预测每个 token 在压缩窗口中重要性
C4 有 Indexer 而 C128 没有¶
原因:
- C4 层在浅层(网络前半部分),信息分辨率高,适合做精细的稀疏 attention token 检索
- C128 层在深层(网络后半部分),每个压缩 token 已经包含了 128 个原始 token 的信息,不需要额外的稀疏检索
- Indexer 使用 MQA attention 从压缩 KV cache 中选择 top-k 个最相关的 token,这个操作的开销与压缩率成正比
静态分配 Ring buffer¶
- 每 token decode 时只需 O(1) 写入(覆盖旧数据),不需要 O(N) 扩展
- 固定大小的 ring buffer 可以预分配在 GPU 显存中,由 CUDA graph 固定
- 写/读位置只需 (seq_len + N - 1) % N 即可计算,无分支
Shadow Radix Cache¶
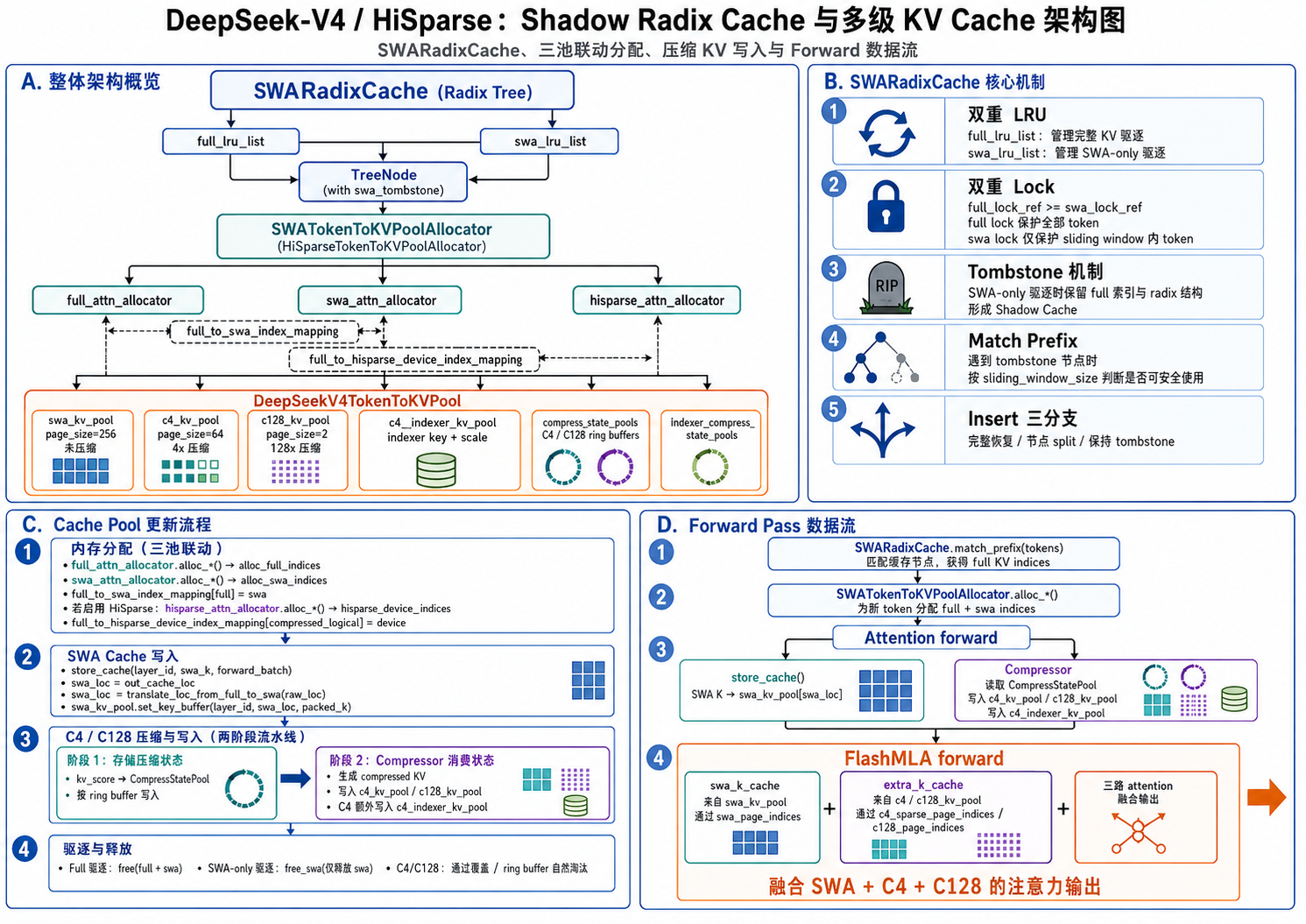
Data Structure¶
- full_lock_ref >= swa_lock_ref —— 有 SWA lock 必有 full lock
- 叶子节点不能是 tombstone —— 如果叶子成了 tombstone,会自动被级联删除
- full_lru_list:控制完整 KV 的驱逐顺序,所有节点都在其中
- swa_lru_list:控制 仅 SWA 的驱逐顺序,tombstone 节点不在其中
class TreeNode:
children: defaultdict # 子节点
key: RadixKey # token 序列
value: Tensor # KV cache 的 full 索引 (物理地址)
swa_tombstone: bool # SWA 是否已释放 (墓碑标记)
full_lock_ref: int # Full cache 锁定计数
swa_lock_ref: int # SWA cache 锁定计数
swa_uuid: int # SWA lock 的边界标识
# 双链 LRU
prev/next # Full LRU 链表
swa_prev/swa_next # SWA LRU 链表
Tombstone 机制¶
Eviction¶
Tombstone 使 SWA 和 Full 的驱逐可以解耦:
- 当 SWA pool 满时,从 swa_lru_list 驱逐:
- 内部节点 → free SWA 索引 → 标记 swa_tombstone=True → 从 swa_lru_list 移除(保留 full KV 索引和 radix 结构)
-
叶子节点 → free 全部索引 → 同时从 full_lru_list 和 swa_lru_list 移除 → 删除节点
-
当 full pool 满时,从 full_lru_list 驱逐叶子节点:
- 释放 full 和 SWA 索引
-
删除叶子,然后迭代删除已经成为叶子的 tombstone 父节点
-
C4/C128 Cache pool 的释放是隐式的
- 当 full token 被释放后,压缩后的位置 不会被重新分配新数据,而是通过 ring buffer / 时间戳自然淘汰。
- 因为 C4/C128 的 page_size 是 full 的 ¼ 或 1/128,数量远少于 full,且每次有新 token 进来时 compressor 会覆盖旧的压缩位置。
Match Prefix¶
前缀匹配中的 tombstone 处理
- 遍历 radix tree 时遇到 tombstone 节点:
- 如果从 tombstone 到当前节点的匹配 token 数 >= sliding_window_size
→ 可以安全使用(SWA 范围内有足够上下文)
- 否则 → 回退到上一个安全点
场景:滑动窗口 = 4, page_size = 1,radix tree 中已有链:
root
→ A: tokens=[0,1], value=[v0,v1], tombstone=True ← SWA 已释放!
→ B: tokens=[2,3], value=[v2,v3], tombstone=False
→ C: tokens=[4,5], value=[v4,v5], tombstone=False
新请求来匹配 tokens [0,1,2,3,4,5]。
结果:返回 6 个 token 的 KV 索引,安全点 = C。
- 从 tombstone A 之后到 C,累积了 4 个 non-tombstone token(B 的 v2,v3 + C 的 v4,v5),恰好等于 SWA 窗口大小。
- 这意味着 SWA cache 中有完整的窗口上下文可用。
场景:如果请求只匹配到 B(tokens [0,1,2,3]):
- 只有 2 个有效 SWA token,不够形成完整窗口,整个匹配结果作废,请求需要重新计算。
Insert¶
场景:radix tree 中有一个 node Q:
新请求要 insert key=[0,1,2,3, 4,5,6,7], value=[new_v0..new_v7], 窗口=4。
遍历到 Q 时:total_prefix_length = 0, prefix_len = 4。
Branch 1:swa_evicted_seqlen = 0 → 全部 SWA 都可恢复
条件: swa_evicted_seqlen (0) <= total_prefix_length (0) ✅
含义: 这个请求的 SWA 在 Q 的范围内没有被驱逐过,可以直接全部恢复。
结果:
Branch 2:swa_evicted_seqlen = 2 → 部分 SWA 被驱逐
条件: swa_evicted_seqlen (2) > total_prefix_length (0) ❌ Branch1
swa_evicted_seqlen (2) < total_prefix_length + prefix_len (4) ✅ Branch2
含义: Q 的前 2 个 token 的 SWA 已被驱逐,后 2 个还在。
结果:
→ Q_new: [0,1], tombstone=True ← SWA 仍然死着
→ child: [2,3], tombstone=False ← SWA 已复活
→ new: [4,5,6,7], tombstone=False
Branch 3:swa_evicted_seqlen = 8 → 全部 SWA 都被驱逐
条件: swa_evicted_seqlen (8) >= total_prefix_length + prefix_len (4) ✅
含义: 整个 Q + 新 token 的 SWA 全没了,什么都不用恢复。
操作: free([new_v0..new_v3]) ← 直接全部释放
继续处理剩余 key
Forward Pass Process¶
1. SWARadixCache.match_prefix(tokens) → 匹配到缓存节点,获得 full KV indices
2. SWATokenToKVPoolAllocator.alloc_*() → 分配新 token 的 full + swa indices
3. Attention forward:
├── store_cache(): SWA K → swa_kv_pool[swa_loc]
└── Compressor:
├── 从 CompressStatePool 读取 ring-buffered kv_score
├── 压缩后写入 c4_kv_pool / c128_kv_pool
└── C4 indexer 写入 c4_indexer_kv_pool
└── 读取 c4_indexer_kv_pool 打分后选 top-k 索引写入 c4_sparse_page_indices
4. FlashMLA forward:
├── swa_k_cache: 从 swa_kv_pool 读取,通过 swa_page_indices 索引
├── extra_k_cache: 从 c4/c128_kv_pool 读取,通过 c4_sparse_page_indices / c128_page_indices
└── 三路 attention 融合输出
Context Parallelism¶
- 当前代码怎么处理 C4/C128 压缩
关键代码在 deepseek_v4.py:285-300:
kv_score = linear_bf16_fp32(x, self.wkv_gate.weight)
if nsa_use_prefill_cp(forward_batch):
kv_score = cp_all_gather_rerange_output(
kv_score,
get_attention_tp_size(),
forward_batch,
torch.cuda.current_stream(),
)
return self.compress_fused(kv_score, forward_batch)
流程是:
每个 rank 先计算自己 token 的 kv_score
↓
cp_all_gather_rerange_output()
↓
每个 rank 都拿到完整顺序的 kv_score:
[t0, t1, t2, t3, t4, t5, ...]
↓
本地执行 compressor
↓
本地写 c4_kv_pool / c128_kv_pool
所以 C4 的 overlap/chunk 依赖在 compressor 里看到的是完整序列,不是 rank-local 的 round-robin 子序列。
- C4 的“前面 chunk 数据”怎么定位
C4/C128 的写位置由 create_paged_compressor_data() 生成,核心逻辑在 compressor.py:210-286:
loc = req_to_token[req_pool_indices, positions]
swa_loc = token_to_kv_pool.translate_loc_from_full_to_swa(loc)
swa_pages = swa_loc // swa_page_size
state_loc = swa_pages * ring_size + swa_loc % ring_size
write_loc = state_loc // compress_ratio
含义:
full KV loc
→ full_to_swa_index_mapping
→ swa_loc
→ state_loc in CompressStatePool ring buffer
→ compressed write_loc
C4 是 overlap compress:
is_overlap = compress_ratio == 4
decode 时还会取:
write_overlap_loc = get_raw_loc(write_positions - compress_ratio)
也就是说 C4 不只是看当前 4-token chunk,还可能需要前一个 C4 chunk 的 overlap 状态。
CP 下这个问题靠前面的 kv_score allgather 解决:compressor 看到的是完整连续序列,所以它可以正确生成 write_loc 和 extra_data。
- SWA cache 怎么处理
SWA 的关键在 MQALayer._forward_prepare(),deepseek_v4.py:784-803:
if self.nsa_enable_prefill_cp and nsa_use_prefill_cp(forward_batch):
kv = cp_all_gather_rerange_output(
kv.contiguous(),
self.cp_size,
forward_batch,
torch.cuda.current_stream(),
)
if self.overlap_store_cache:
attn_backend.store_cache(
layer_id=self.layer_id,
swa_k=kv,
forward_batch=forward_batch,
)
流程:
每个 rank 先算自己 token 的 kv
↓
allgather + rerange
↓
每个 rank 得到完整顺序 kv:
[t0, t1, t2, ...]
↓
store_cache 写入本地 swa_kv_pool
store_cache() 里再做:
raw_loc = forward_batch.out_cache_loc
swa_loc = translate_loc_from_full_to_swa(raw_loc)
swa_kv_pool.set_key_buffer(layer_id, swa_loc, swa_k)
所以 SWA cache 的写入是:
完整 kv tensor + 全局 out_cache_loc
→ 翻译到 swa_loc
→ 每个 rank 本地写完整 SWA cache
这避免了后续 FlashMLA attention 需要跨 rank 读 SWA KV。
- KV cache 到底是不是跨 rank 共享?
不是物理共享。
更准确地说:
每个 CP rank / GPU 都有自己的 KV cache pool
但 allocator / req_to_token / out_cache_loc 是对称的
所以逻辑 KV index 在各 rank 上一致
因此:
- rank0 的 logical loc 1234 和 rank1 的 logical loc 1234 表示各自本地 KV pool 的同一个逻辑位置。
- CP 通过 allgather 让每个 rank 都把完整 KV 写到自己的本地 pool。
- 后续 attention 只读本 rank 本地 KV cache,不做 remote KV read。
这是当前实现的核心取舍:
多做 allgather + 重复写本地 KV
换取后续 attention/compressor/cache 逻辑仍然保持本地、简单、对称
- Shadow prefix / SWARadixCache 这边怎么配合
SWARadixCache 本身不感知 CP。
它仍然管理全局 token 序列:
tokens: [t0,t1,t2,t3,t4,...]
value: [full_loc0, full_loc1, full_loc2,...]
CP 发生在模型 forward 内部:
hidden_states 被切分
attention metadata 被切分
KV 写入前又 allgather 回完整顺序
Radix cache 的 insert/match 仍然面对完整前缀:
match_prefix → 返回全局 prefix_indices
insert → 插入完整 token_ids + full kv indices
所以 shadow prefix cache 不需要维护 per-rank prefix。
代价¶
代价 1:KV / kv_score allgather
C4 和 SWA 都需要完整连续序列,因此每层都可能有:
local kv / kv_score
→ allgather
→ rerange
长 prefill 下通信量不小。
代价 2:每个 rank 重复写完整 KV cache
每个 rank 都写一份完整的 SWA/C4/C128 cache。这减少了 remote read 复杂度,但增加了显存和写带宽。
代价 3:chunked prefill 风险
代码里有 debug assert 提醒:
extend_seq_lens != seq_lens
→ chunked-prefill continuation
→ CP round-robin may have domain mismatch
因为后续 chunk 的 token-to-rank 分布、已有 KV cache 的顺序、compress state ring 的连续性都更复杂。
MegaMoE¶
适合的场景
| 条件 | 原因 |
|---|---|
| decode 阶段 (batch size 小) | token 数少,符合 <=1024 限制,kernel launch 开销占比大 |
| DeepSeek-V4 / V3 系列 | 这些模型的 FP4 MoE 权重格式天然适配 |
| 单卡或小规模 EP | 不需要复杂的 expert-parallel 通信 |
| FP8 推理 | MegaMoE 深度依赖 FP8/FP4 量化路径 |
| prefill 的 chunk 较小 | 同样满足 token 数限制 |
不适合的场景
| 条件 | 原因 |
|---|---|
| 大批量 prefill (token > 1024) | 超过 NUM_MAX_TOKENS_PER_RANK 上限,自动回退 |
| hash-routed 模型 | 路由方式不同,需要额外适配 (FIX_HASH_MEGA_MOE) |
| 投机解码 (NextN/MTP) | 被显式排除 (self.is_nextn → False) |
| 需要跨节点 EP | MegaMoE 不走 DeepEP 通信,不适合大规模分布式 |
| BF16 权重模型 | 依赖 FP4 权重和 UE8M0 scale 格式 |