2.2 内存模型
volatile访问不会建立线程间的同步。- 此外,
volatile访问不是原子的(并发读写是一个数据竞争问题),并且不会对内存进行排序(非volatile的内存访问可以自由地在volatile访问周围重新排序)。
2.2.1 协议级别
- 原子操作的顺序一致语义被称为强内存模型,原子操作的自由语义被称为弱内存模型。
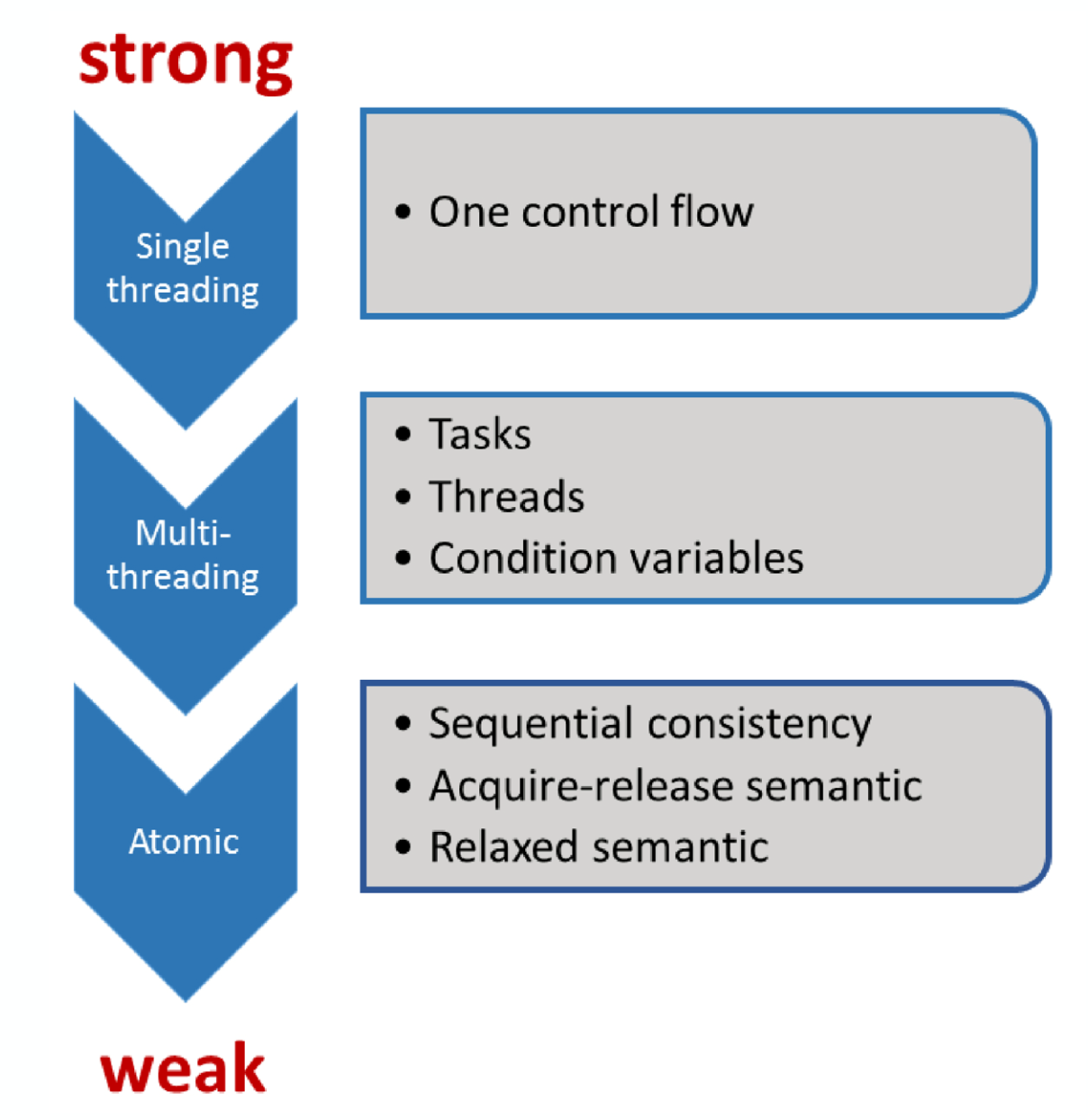
2.2.2 C++的内存序
原子操作默认的内存序是std::memory_order_seq_cst,顺序一致性
enum memory_order{
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
}
-
顺序一致:
memory_order_seq_cst -
获取-释放(Acquire-release):
memory_order_consume,memory_order_acquire,memory_order_release和memory_order_acq_rel -
自由序(Relaxed):
memory_order_relaxed
Sequentially-consistent ordering
顺序一致中,一个线程可以看到另一个线程的操作,因此也可以看到所有其他线程的操作。如果使用原子操作的获取-释放语义,那么顺序一致就不成立了。
- 标记为memory_order_seq_cst的原子操作不仅像释放/获取顺序那样对内存进行排序(一个线程中在存储操作之前发生的所有事情都成为另一个线程中加载操作的可见副作用),而且建立了一个所有这样标记的原子操作的单一总修改顺序。
Release-Acquire ordering
- 如果线程A中的原子存储操作标记为
memory_order_release,而线程B中对同一变量的原子加载操作标记为memory_order_acquire,并且线程B中的加载操作读取了线程A中存储操作写入的值,那么线程A中的存储操作与线程B中的加载操作之间就建立了同步关系(synchronizes-with)。 所有在原子存储操作之前发生(从线程A的角度看)的内存写入操作(包括非原子操作和标记为memory_order_relaxed的原子操作)都将成为线程B中可见的副作用。也就是说,一旦原子加载操作完成,线程B将能够看到线程A写入的所有内容。这种保证仅在B实际返回线程A存储的值,或者返回释放序列中更晚的值时才成立。 - 这种同步仅在释放和获取同一原子变量的线程之间建立。其他线程可能会看到与同步线程之一或两者都不同的内存访问顺序。。
互斥锁(如std::mutex或原子自旋锁)是释放-获取同步的一个例子:当线程A释放锁,线程B获取锁时,线程A在释放锁之前在临界区中发生的所有操作都必须对线程B可见(线程B在获取锁之后执行相同的临界区)。 同样的原理也适用于线程的启动和汇入。这两种操作都是获取-释放操作。接下来是wait和notify_one对条件变量的调用;wait是获取操作,notify_one是释放操作。那notify_all呢?当然,也是一个释放操作。
- 在一个释放序列中,即使RMW操作使用了memory_order_relaxed,它也不会破坏释放序列的同步效果。
#include <atomic>
#include <cassert>
#include <thread>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1()
{
data.push_back(42);
flag.store(1, std::memory_order_release);
}
void thread_2()
{
int expected = 1;
// memory_order_relaxed is okay because this is an RMW,
// and RMWs (with any ordering) following a release form a release sequence
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_relaxed))
{
expected = 1;
}
}
void thread_3()
{
while (flag.load(std::memory_order_acquire) < 2)
;
// if we read the value 2 from the atomic flag, we see 42 in the vector
assert(data.at(0) == 42); // will never fire
}
int main()
{
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join(); b.join(); c.join();
}
- 错误案例
dataProduced.store(true, std::memory_order_release)与dataProduced.load(std::memory_order_acquire)同步。不过,并不意味着获取操作要对释操作进行等待,而这正是下图中的内容。图中,dataProduced.load(std::memory_order_acquire)在指令dataProduced.store(true, std::memory_order_release)之前,所以这里没有同步关系。

// acquireReleaseWithoutWaiting.cpp
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::vector<int> mySharedWork;
std::atomic<bool> dataProduced(false);
void dataProducer(){
mySharedWork = {1,0,3};
dataProduced.store(true, std::memory_order_release);
}
void dataConsumer(){
dataProduced.load(std::memory_order_acquire);
myShraedWork[1] = 2;
}
int main(){
std::cout << std::endl;
std::thread t1(dataConsumer);
std::thread t2(dataProducer);
t1.join();
t2.join();
for (auto v : mySharedWork){
std::cout << v << " ";
}
std::cout << "\n\n";
}
- 当dataProduced.store(true, std::memory_order_release)先行于dataProduced.load(std::memory_order_acquire),那么dataProduced.store(true, std::memory_order_release)之前和dataProduced.load(std::memory_order_acquire)之后执行的操作是所有线程可见的。
Relax Ordering
Typical use for relaxed memory ordering is incrementing counters, such as the reference counters of std::shared_ptr, since this only requires atomicity, but not ordering or synchronization (note that decrementing the std::shared_ptr counters requires acquire-release synchronization with the destructor).
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::atomic<int> cnt = {0};
void f()
{
for (int n = 0; n < 1000; ++n)
cnt.fetch_add(1, std::memory_order_relaxed);
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n)
v.emplace_back(f);
for (auto& t : v)
t.join();
std::cout << "Final counter value is " << cnt << '\n';
}
// always 10000