Database
- 这里记录了一些数据库相关基础知识和一些论文选读
Chapter 1 CMU15445
- 该章节分为两部分lecture和lab
- lecture是对课上知识点的回顾
- lab是对应的配套练习
Lecture
分布式数据库系统介绍
分布式 OLTP 数据库技术
分布式 OLAP 数据库技术
Distributed System
- 这里记录了一些分布式系统相关基础知识和一些论文选读
raft 论文笔记
raft 解决的问题
通过领导者的方式,Raft 将一致性问题分解成了三个相对独立的子问题:
-
领导者选举:启动集群时以及现有领导者失败时必须选出新的领导者。
-
日志复制:领导者必须接受来自客户端的日志条目,并在整个集群中复制它们,迫使其他日志与其自己的日志一致。
-
安全性:Raft 的安全属性的关键是图 3.2 中的状态机安全性属性:如果任何服务器已将特定的日志条目应用于其状态机,则其他服务器都不可以对同一日志索引应用不同的命令。第 3.6 节介绍了 Raft 如何确保此属性;这个解决方案涉及对第 3.4 节中所述的选举机制的额外限制。

raft 领导者选举问题
这里可能出现无限选举瓜分的情况
第三种可能的结果是候选人既没有赢得选举也没有输:如果有多个跟随者同时成为候选人,那么选票可能会被瓜分以至于没有候选人可以赢得大多数人的支持。当这种情况发生的时候,每一个候选人都会超时,然后通过增加当前任期号来开始一轮新的选举。然而,没有其他机制的话,选票可能会被无限的重复瓜分
- 这里使用随机选举超时时间来确保选票瓜分情况出现频率较低
选举超时时间是从一个固定的区间(例如 150-300 毫秒)随机选择。这样可以把服务器都分散开以至于在大多数情况下只有一个服务器会选举超时;然后他赢得选举并在其他服务器超时之前发送心跳包。同样的机制被用在选票瓜分的情况下。每一个候选人在开始一次选举的时候会重置一个随机的选举超时时间,然后在超时时间内等待投票的结果;这样减少了在新的选举中另外的选票瓜分的可能性。
raft 日志复制
- 领导者针对每一个跟随者维护了一个 nextIndex,这表示下一个需要发送给跟随者的日志条目的索引地址。当一个领导者刚获得权力的时候,他初始化所有的 nextIndex 值为自己的最后一条日志的 index 加 1。
如果一个跟随者的日志和领导者不一致,那么在下一次的附加日志 RPC 时的一致性检查就会失败。在被跟随者拒绝之后,领导者就会减小 nextIndex 值并进行重试。最终 nextIndex 会在某个位置使得领导者和跟随者的日志达成一致。当这种情况发生,附加日志 RPC 就会成功,这时就会把跟随者冲突的日志条目全部删除并且加上领导者的日志。一旦附加日志 RPC 成功,那么跟随者的日志就会和领导者保持一致,并且在接下来的任期里一直继续保持。 优化1:在领导者发现它与跟随者的日志匹配位置之前,领导者可以发送不带任何条目(例如心跳)的附加日志 RPCs 以节省带宽。 然后,一旦 matchIndex 恰好比 nextIndex 小 1,则领导者应开始发送实际条目。 优化2:算法可以通过减少被拒绝的附加日志 RPCs 的次数来优化。例如,当附加日志 RPC 的请求被拒绝的时候,跟随者可以包含冲突的条目的任期号和自己存储的那个任期的最早的索引地址。
raft 安全性
选举限制
- 日志条目的传送是单向的,只从领导者传给跟随者,并且领导者从不会覆盖自身本地日志中已经存在的条目。
- 请求投票 RPC 实现了这样的限制: RPC 中包含了候选人的日志信息,然后投票人会拒绝掉那些日志没有自己新的投票请求。
日志“新”的定义:Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
- Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导者当前任期里的日志条目通过计算副本数目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。
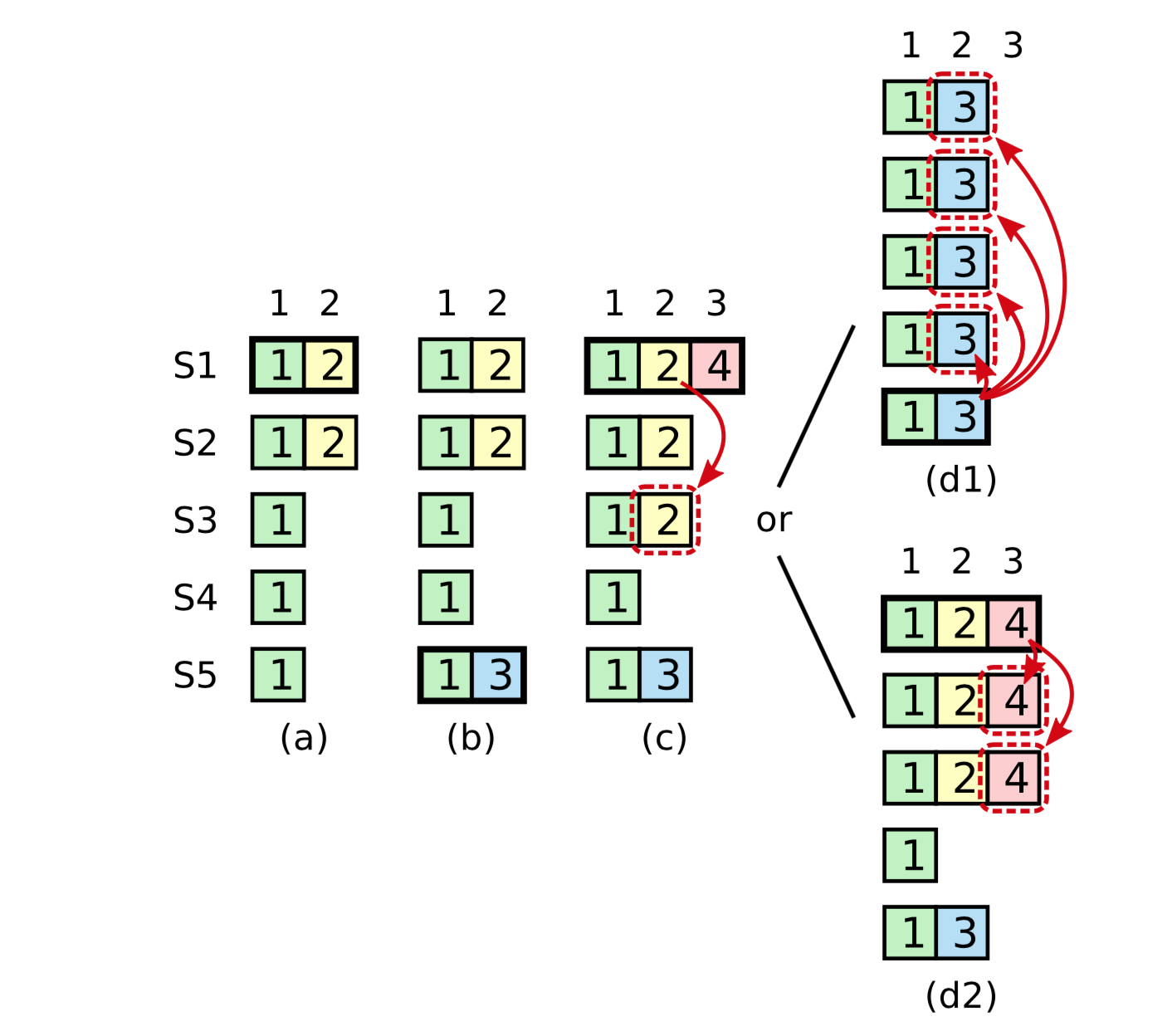
在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一0000000条不一样的日志条目放在了索引 2 处。然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。如果 S1 在 (d1) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (d2) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
故障情况处理
follower 和 candidate 崩溃
- Raft 中处理这种失败就是简单的通过无限的重试;如果崩溃的机器重启了,那么这些 RPC 就会完整的成功。如果一个服务器在完成了一个 RPC,但是还没有响应的时候崩溃了,那么在他重新启动之后就会再次收到同样的请求。
- Raft 的 RPCs 都是幂等的,所以这样重试不会造成任何问题。
持久化状态和服务重启
- 每一个服务器需要持久化当前的任期和投票选择
以防止服务器在相同的任期内投票两次,或者将新领导者的日志条目替换为废弃领导者的日志条目。
- 每一个服务器也要在统计日志提交状态之前持久化该日志
这可以防止已经提交的条目在服务器重启时丢失或“未提交”。
raft kv server 设计
这里的设计均是来自于 pingcap 公司的 Tinykv项目
总体设计
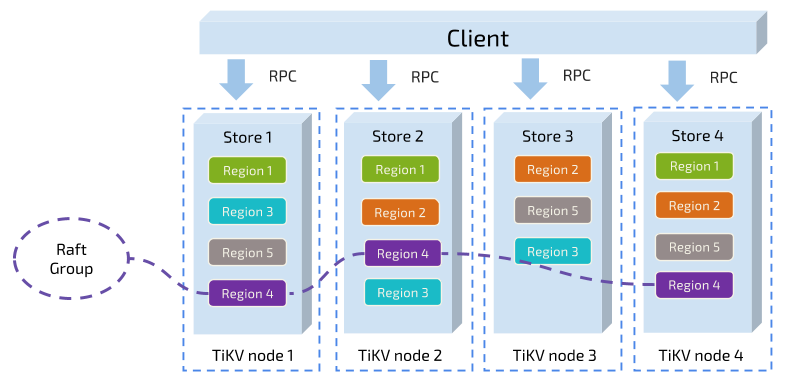
术语
- Store: 每个节点叫做 Store
- RaftStore: 位于 Store 中,每个 Store 一个 RaftStore,用于监听用户的事件并与下层的 raft 层进行交互,同时需要与同一 Raft Group 的 peer 相互通信
- Peer: 每个 Raft 中的 leader/candidate/follower,每个 RaftStore 中包含多个 peer,每个 peer 是来自不同的 Raft Group,所有的 peer 共用同一个底层存储
- Region: 一个 Region 叫做一个 Raft Group,一个 region 包含多个 peer,这些 peer 散落在不同的 RaftStore 上。Region 处理的是某一个范围的数据。比如 Region A 处理 $0 \le key \le split$,Region B 处理 $split \leq key \le MAX$,两个 Region 各司其职,互不干涉,均有自己的 Leader。
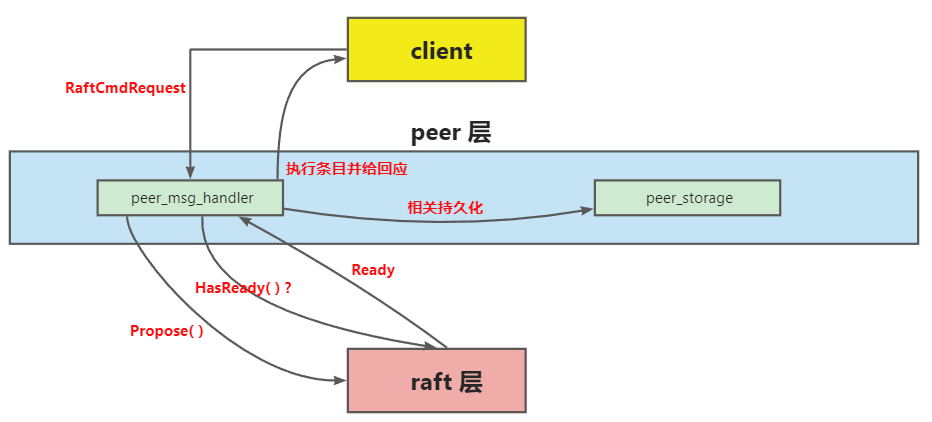
层次架构
- Raft 层: Rawnode-Raft-RaftLog 统称为 raft 层,raft 层收到 peer 层传来的 entry 后,会在集群内部进行同步
- peer 层: 实际上是 RaftStore 的部分模块,接收来自 client 的 RaftCmdRequest,其中包含着不同的命令请求,接着它会把这些请求逐一以 entry 的形式传递给 raft 层,当然,这个 peer 应该是 Leader,不然 client 会找下一个 peer 继续试。同时,peer 会向 raft 请求 Ready 结构体,对已经同步的数据进行持久化
- client 层: 向 RaftKV 发出请求
用户的操作
1: "Get": 获取 key 对应的 value 3: "Put": 插入 key-value 对 4: "Delete": 根据 key 删除 key-value 对 5: "Snap": 为当前状态生成快照?
工作流程
- RaftStore 在节点启动被创建,它负责维护在该节点上所有的 region 和对应的 peer
type Raftstore struct { ctx *GlobalContext storeState *storeState router *router // 路由的作用,在这里维护<region id, peer>对应关系 workers *workers // 可以看作是线程池,都是处理用户传来的消息 tickDriver *tickDriver closeCh chan struct{} wg *sync.WaitGroup } - 接着,RaftStore 会加载 peers,然后将 peers 注册进 router。加载 peer 的时候如果底层存储着之前 peer 信息,那么根据存储的信息加载,否则就新建。
- 启动一系列的 worker。RaftStore 的主要工作你可以认为就是接收来自其他节点的 msg,然后根据 msg 里面的 region id 将其路由到指定 region 的 peer 上。同时 RaftStore 也会将 peer 获取需要发送给其他节点的信息,发到其他的 RaftStore 上。
RaftWorker 工作流程
- 不停的处理收到的 msg,然后根据 RawNode 传来的 ready 持久化当前 peer 的状态
HandleMsg是一个 switch,根据 msg 的类型进行不同的处理HandleRaftReady处理 RawNode 产生的 Ready
// run runs raft commands.
// On each loop, raft commands are batched by channel buffer.
// After commands are handled, we collect apply messages by peers, make a applyBatch, send it to apply channel.
func (rw *raftWorker) run(closeCh <-chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
var msgs []message.Msg
for {
msgs = msgs[:0]
select {
case <-closeCh:
return
case msg := <-rw.raftCh:
msgs = append(msgs, msg)
}
pending := len(rw.raftCh)
for i := 0; i < pending; i++ {
msgs = append(msgs, <-rw.raftCh)
}
peerStateMap := make(map[uint64]*peerState)
for _, msg := range msgs {
peerState := rw.getPeerState(peerStateMap, msg.RegionID)
if peerState == nil {
continue
}
newPeerMsgHandler(peerState.peer, rw.ctx).HandleMsg(msg)
}
for _, peerState := range peerStateMap {
newPeerMsgHandler(peerState.peer, rw.ctx).HandleRaftReady()
}
}
}
HandleRaftReady 工作流程
- 判断是否有新的 Ready,没有就什么都不处理
- 调用 SaveReadyState 将 Ready 中需要持久化的内容保存到 KV 数据库。如果 Ready 中存在 snapshot,则处理它
- 调用 Send 将 Ready 中的 Msg 发出去
- 应用 Ready 中的 CommittedEntries
最后调用 proposal 进行回复处理
- 调用 Advance 推进 Raft 层的同步过程
Proposal 回复处理
- 需要考虑过时的 entry,落后的 leader 等边界情况
for len(d.proposals) > 0 {
proposal := d.proposals[0]
if entry.Term < proposal.term {
return
}
if entry.Term > proposal.term {
proposal.cb.Done(ErrRespStaleCommand(proposal.term))
d.proposals = d.proposals[1:]
continue
}
if entry.Term == proposal.term && entry.Index < proposal.index {
return
}
if entry.Term == proposal.term && entry.Index > proposal.index {
proposal.cb.Done(ErrRespStaleCommand(proposal.term))
d.proposals = d.proposals[1:]
continue
}
if entry.Index == proposal.index && entry.Term == proposal.term {
if resp.Header == nil {
resp.Header = &raft_cmdpb.RaftResponseHeader{}
}
if isExecSnap {
proposal.cb.Txn = d.peerStorage.Engines.Kv.NewTransaction(false) // 注意时序,一定要在 Done 之前完成
}
// proposal.cb.Txn = txn
proposal.cb.Done(resp)
d.proposals = d.proposals[1:]
return
}
panic("This should not happen.")
}
snap 工作流程
- 在
d.onRaftGCLogTick()中通过检查appliedIdx - firstIdx >= d.ctx.cfg.RaftLogGcCountLimit来决定是否进行日志删除。如果是,那么就通过 proposeRaftCommand() 提交一个AdminCmdType_CompactLog下去,当该 Request 被集群同步完成并在 HandleRaftReady 中执行时,会被交给 raftlog_gc.go 来实现删除。 - 删除完日志后,节点会更新自己的
applyState.TruncatedState.Index,该字段指已经被删除的最后一条日志,即该日志之后均没有被删除。
snap 的生成
- 因为 Snapshot 很大,不会马上生成,这里为了避免阻塞,生成操作设为异步,如果 Snapshot 还没有生成好,Snapshot 会先返回 raft.ErrSnapshotTemporarilyUnavailable 错误,Leader 就应该放弃本次 Snapshot,等待下一次再次请求 Snapshot。